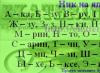Вирішив трохи подужати Python, але долає "аби не пхп" не цікаво. Корисливим інтересом стало авторазгадиваніе капчи Python.
Почалося справу постом з Хабра від 2012 (графічна бібліотека взагалі 2009 року).
Код: https://habrahabr.ru/post/149091/
У мене з коробки варто 2.7.10, а код писався під 2.5 (з либой PIL). Пишуть, що на 2.7.3 відмінно запускається.
PIL накотив так ось
Код: # download
curl -O -L http://effbot.org/media/downloads/Imaging-1.1.7.tar.gz
# extract
tar -xzf Imaging-1.1.7.tar.gz
cd Imaging-1.1.7
# Build and install
python setup.py build
sudo python setup.py install
# Or install it for just you without requiring admin permissions:
# Python setup.py install --user
Потім імпортував модуль так ось
Код: # набрати в консольку
python
# Включиться інтерпретатор, якому скомандувати
import PIL
# Якщо все ок, натиснути Ctrl + D для виходу
Змеюка не дружить з кирилицею, в початок файлу додав конструкцію (щоб стало можливо комментить саморобку кореляцій)
Код: # - * - coding: utf-8 - * -
Ось сам велосипед (не вмію писати цикли і не знаю як eval, тому багато підставляв руками).
Код: # - * - coding: utf-8 - * -
# Ця херь потрібна для російських символів
from PIL import Image
from operator import itemgetter
im = im.convert ( "P")
his = im.histogram ()
values = ()
for i in range (256):
values [i] = his [i]
for j, k in sorted (values.items (), key = itemgetter (1), reverse = True) [: 15]:
print "or pix ==", j #, k
# В змінної j зберігаються десять найпопулярніших квітів
from PIL import Image
im = Image.open ( "captcha.gif")
im = im.convert ( "P")
im = im.convert ( "P")
for x in range (im.size):
for y in range (im.size):
pix = im.getpixel ((y, x))
temp = pix
# Сюди кольору
im2.putpixel ((y, x), 0)
im2.save ( "output.gif")
# Тут начебто знову все з початку
from PIL import Image
im = Image.open ( "output.gif")
im = im.convert ( "P")
im2 = Image.new ( "P", im.size, 255)
im = im.convert ( "P")
for x in range (im.size):
for y in range (im.size):
pix = im.getpixel ((y, x))
temp = pix
if pix == 255: # these are the numbers to get
im2.putpixel ((y, x), 0)
# New code starts here
inletter = False
foundletter = False
start = 0
end = 0
pix = im2.getpixel ((y, x))
if pix! = 255:
inletter = True
foundletter = True
start = y
foundletter = False
end = y
letters.append ((start, end))
Inletter = False
print letters
#хто зна
class VectorCompare:
def magnitude (self, concordance):
total = 0
for word, count in concordance.iteritems ():
total + = count ** 2
return math.sqrt (total)
Def relation (self, concordance1, concordance2):
relevance = 0
topvalue = 0
for word, count in concordance1.iteritems ():
if concordance2.has_key (word):
topvalue + = count * concordance2
return topvalue / (self.magnitude (concordance1) * self.magnitude (concordance2))
# Набір символів
from PIL import Image
import hashlib
import time
im = Image.open ( "captcha.gif")
im2 = Image.new ( "P", im.size, 255)
im = im.convert ( "P")
print im.histogram ()
for x in range (im.size):
for y in range (im.size):
pix = im.getpixel ((y, x))
temp = pix
# Сюди кольору
if pix == 187 or pix == 224 or pix == 188 or pix == 223 or pix == 145 or pix == 151 or pix == 181 or pix == 144 or pix == 225 or pix == 182 or pix == 189 or pix == 12 or pix == 17 or pix == 139 or pix == 152: # or pix ==
im2.putpixel ((y, x), 0)
inletter = False
foundletter = False
start = 0
end = 0
for y in range (im2.size): # slice across
for x in range (im2.size): # slice down
pix = im2.getpixel ((y, x))
# Тут було "не дорівнює 255" тобто - було "не дорівнює білому"
if pix == 255:
inletter = True
If foundletter == False and inletter == True:
foundletter = True
start = y
If foundletter == True and inletter == False:
foundletter = False
end = y
letters.append ((start, end))
inletter = False
# New code is here. We just extract each image and save it to disk with
# What is hopefully a unique name
count = 0
for letter in letters:
m = hashlib.md5 ()
im3 = im2.crop ((letter, 0, letter, im2.size))
m.update ( "% s% s"% (time.time (), count))
im3.save ( "./% s.gif"% (m.hexdigest ()))
count + = 1
Принцип роботи такий: скласти гістограму, прибрати самий часті відтінки, що залишився перезберегти чорно-білим, розбити по межах символів, порівнювати символи із зразками.
Оригінальна капча, без 10 популярних відтінків, без 15 популярних відтінків (розбивати на символи не став - бо є нецілі символ).
Оригінальна капча, без 15 популярних відтінків, розбита на 2 символи (брудно).
Під просту капчу цілком реально запив разгадиватель. Потрібні цікаві місця з простими капч для допилювання і обкатки.
Доброго часу доби! Нещодавно, під деякі потреби потрібна капча на Python'e від «цікавих». Подивився в Google і нічого нормального без Djangoне побачив. В результаті дійшов висновку, що напишу не як окреме WSGIдодаток, а просто CGIскриптом.
Для роботи з зображеннями був обраний пакет Python Imaging Library. На жаль PIL дає кілька мізерні можливості в порівнянні з GD2 в PHP.
Завантажити пакет для Python версій 2 і 3 можна від сюди: http://www.lfd.uci.edu/~gohlke/pythonlibs/
Відразу хочу зауважити, що використовується Python 3.1, Хоча я думаю що на Python 2.6+ він теж запуститися.
І так, в результаті ми повинні отримати генерацію зображення з 5-6 символів на різнобарвному тлі.
Так як архів з усім готовим я тут не викладаю, все будемо робити по керівництву.
Каталоги і їх ієрархія:
Cgi-bin
-captcha
-backgrounds
-fonts
-index.py
Думаю з цим зрозуміло, що в папці cgi-bin лежить папка captcha в якій лежать backgrounds і fonts і сам скрипт index.py.
Тепер нам потрібні бекграунд. Вбиваємо «backgrounds» в Google.Картінкі і качаємо штук 15-20. І потрібно зробити такі прямокутники розміром 200х60 px в форматі JPEG.
Все кидаємо в папку backgrounds.
Тепер шрифти. Нас цікавлять TrueTypeшрифти (* .ttf). Беремо штук 15 шрифтів позаковирістей і кидаємо в папку fonts.
Все бекграунд є, шрифти є, тепер сам index.py.
Print ( "Content-Type: image / jpeg"); print ( ""); import sys, os, re, random from PIL import Image, ImageFont, ImageDraw class captcha (object): def __init __ (self): self.string = ""; self.root = os.getcwd (); self.path_backgrounds = self.root + "/ backgrounds /"; self.path_fonts = self.root + "/ fonts /"; def gen_string (self): chars = ( "a", "b", "d", "e", "f", "g", "h", "j", "m", "n", " q "," r "," t "," u "," y "," A "," B "," D "," E "," F "," G "," H "," J " , "M", "N", "Q", "R", "T", "U", "Y", "1", "2", "3", "4", "5", " 6 "," 7 "," 8 "," 9 "); for i in range (random.randint (5, 6)): self.string + = chars; return self.string; def gen_backgrounds (self): images =; if os.path.exists (self.path_backgrounds): for f in os.listdir (self.path_backgrounds): if os.path.isdir (self.path_backgrounds + "/" + f): continue; if re.search ( "\. (jpeg | jpg) $", f, re.IGNORECASE): images.append (self.path_backgrounds + "/" + f); else: sys.exit (); if len (images) == 0: sys.exit (); return images; def gen_fonts (self): fonts =; if os.path.exists (self.path_fonts): for f in os.listdir (self.path_fonts): if os.path.isdir (self.path_fonts + "/" + f): continue; if re.search ( "\. (ttf) $", f, re.IGNORECASE): fonts.append (self.path_fonts + "/" + f); else: sys.exit (); if len (fonts) == 0: sys.exit (); return fonts; def gen_image (self): string = self.gen_string (); backgrounds = self.gen_backgrounds (); fonts = self.gen_fonts (); image = Image.new ( "RGB", (200,60), "#FFF") draw = ImageDraw.Draw (image); for i in range (5): background = Image.open (backgrounds); x = random.randint (0, 160); cp = background.crop ((x, 0, x + 40, 60)); image.paste (cp, (i * 40, 0)); if len (string) == 5: x = random.randint (25, 30); else: x = random.randint (8, 11); for char in string: font = fonts; y = random.randint (5, 25); font_size = random.randint (24, 30); color_dark = "rgb (" + str (random.randint (0,150)) + "," + str (random.randint (0,100)) + "," + str (random.randint (0,150)) + ")"; color_font = "rgb (" + str (random.randint (50,200)) + "," + str (random.randint (0,150)) + "," + str (random.randint (50,200)) + ")"; ttf = ImageFont.truetype (font, font_size) draw.text ((x + 1, y + 1), char, fill = color_dark, font = ttf) draw.text ((x, y), char, fill = color_font, font = ttf) x + = random.randint (13, 15) + 18; image.save (sys.stdout, "JPEG") cp = captcha (); cp.gen_image (); # Cp.string; рядок символів
От і все. У мене за адресою http: //localhost/cgi-bin/captcha/index.py генерується зображення. Далі можна дописати механізм зберігання генерованої рядки ( cp.string) З сесіях або ще де-небудь.
Є різні способи для обходу CAPTCHA, якими захищені сайти. По-перше, існують спеціальні сервіси, які використовують дешевої ручної праці і буквально за $ 1 пропонують вирішити 1000 капч. В якості альтернативи можна спробувати написати інтелектуальну систему, яка за певними алгоритмами буде сама виконувати розпізнавання. Останнє тепер можна реалізувати за допомогою спеціальної утиліти.
вирішити CAPTCHA
Розпізнавання CAPTCHA - завдання найчастіше нетривіальна. На зображення необхідно накладати масу різних фільтрів, щоб прибрати спотворення і перешкоди, якими розробники хочуть зміцнити стійкість захисту. Найчастіше доводиться реалізовувати навчальну систему на основі нейронні мереж (це, до речі, не так складно, як може здатися), щоб добитися прийнятного результату по автоматизованому рішенню капч. Щоб зрозуміти, про що я говорю, краще підняти архів і прочитати чудові статті «Злом CAPTCHA: теорія і практика. Розбираємося, як ламають капчи »і« підглянуті і розпізнаємо. Злом Captcha-фільтрів »з # 135 і # 126 номерів відповідно. Сьогодні ж я хочу розповісти тобі про розробку TesserCap, яку автор називає універсальної решалкой CAPTCHA. Цікава штука, як не крути.Перший погляд на TesserCap
Що зробив автор програми? Він подивився, як зазвичай підходять до проблеми автоматизованого рішення CAPTCHA і спробував узагальнити цей досвід в одному інструменті. Автор зауважив, що для видалення шумів з зображення, тобто рішення найскладнішого завдання при розпізнаванні капч, найчастіше застосовуються одні і ті ж фільтри. Виходить, що якщо реалізувати зручний інструмент, що дозволяє без складних математичних перетворень накладати фільтри на зображення, і поєднати його з OCR-системою для розпізнавання тексту, то можна отримати цілком працездатну програму. Це, власне, і зробив Гурс Сінгх Калре з компанії McAfee. Навіщо це було потрібно? Автор утиліти вирішив таким чином перевірити, наскільки безпечні капчи великих ресурсів. Для тестування були обрані ті інтернет-сайти, які є найбільш відвідуваними за версією відомого сервісу статистики. Кандидатами на участь у тестуванні стали такі монстри, як Wikipedia, eBay, а також провайдер капч reCaptcha. Якщо розглядати в загальних рисах принцип функціонування програми, то він досить простий. Вихідна капча надходить в систему попередньої обробкизображень, очищає капчу від всяких шумів і спотворень і по конвеєру передавальної отримане зображення OCR-системі, яка намагається розпізнати текст на ньому. TesserCap має інтерактивний графічний інтерфейс і має такі властивості:- Має універсальну систему попередньої обробки зображень, яку можна налаштувати для кожної окремої капчи.
- Включає в себе систему розпізнавання Tesseract, яка витягує текст з попередньо проаналізованого і підготовленого CAPTCHA-зображення.
- Підтримує використання різних кодувань в системі розпізнавання.
 Попередня обробка зображень і витяг
Попередня обробка зображень і витяг тексту з капчі
About
Ми не могли не сказати хоча б пари слів про автора чудової утиліти TesserCap. Його звуть Гурс Сінгх Калре. Він працює головним консультантом в підрозділі професійних послуг Foundstone, яке входить до складу компанії McAfee. Гурс виступав на таких конференціях, як ToorCon, NullCon і ClubHack. Є автором інструментів TesserCap і SSLSmart. Крім цього, розробив кілька інструментів для внутрішніх потреб компанії. Улюблені мови програмування - Ruby, Ruby on Rails і C #. Підрозділ професійних послуг Foundstone®, в якому він працює, пропонує організаціям експертні послуги та навчання, забезпечує постійну і дієвий захист їхніх активів від найсерйозніших загроз. Команда підрозділи професійних послуг складається з визнаних експертів у галузі безпеки і розробників, які мають багатий досвід співпраці з міжнародними корпораціями та державнимиІнтерфейс. вкладка Main
Після запуску програми перед нами постає вікно з трьома вкладками: Main, Options, Image Preprocessing. Основна вкладка містить елементи управління, які використовуються для запуску і зупинки тесту CAPTCHA-зображення, формування статистики тесту (скільки відгадане, а скільки ні), навігації та вибору зображення для попередньої обробки. В поле для введення URL-адреси (елемент управління № 1) повинен бути вказаний точний URL-адресу, який веб-додаток використовує для вилучення капч. URL-адресу можна отримати наступним чином: клікнути в правій частині CAPTCHA-зображення, скопіювати або переглянути код сторінки і витягти URL-адресу з атрибута src тега зображення ..сайт / common / rateit / captcha.asp ?. Поруч з рядком адреси знаходиться елемент, що задає кількість капч, які потрібно завантажити для тестування. Так як додаток може одночасно показувати тільки 12 зображень, в ньому передбачені елементи управління для посторінкового гортання завантажених капч. Таким чином, при масштабному тестуванні ми зможемо перегортати завантажені капчи і переглядати результати їх розпізнавання. Кнопки Start і Stop запускають і зупиняють тестування відповідно. Після тестування потрібно оцінити результати розпізнавання зображень, зазначивши кожен з них як коректний або некоректний. Ну і остання, найбільш значуща функція служить для передачі будь-якого зображення в систему попередньої обробки, в якій задається фільтр, що видаляє з зображення шуми і спотворення. Щоб передати картинку в систему попередньої обробки, треба клацнути на необхідному зображенні правою кнопкою миші і в контекстному менювибрати пункт Send To Image Preprocessor.Інтерфейс. вкладка Options
Вкладка опцій містить різні елементи керування для конфігурації TesserCap. Тут можна вибрати OCR-систему, задати параметри веб-проксі, включити переадресацію і попередню обробку зображень, додати користувацькі HTTP-заголовки, а також вказати діапазон символів для системи розпізнавання: цифри, букви в нижньому регістрі, букви в верхньому регістрі, спеціальні символи. Тепер про кожну опції детальніше. Перш за все, можна вибрати OCR-систему. За замовчуванням доступна тільки одна - Tesseract-ORC, так що морочитися з вибором тут не доведеться. Ще одна дуже цікава можливість програми - вибір діапазону символів. Візьмемо, наприклад, капчу з сайт - видно, що вона не містить жодної букви, а складається тільки з цифр. Так навіщо нам зайві символи, які тільки збільшать ймовірність некоректного розпізнавання ?. Але що якщо вибрати Upper Case? Чи зможе програма розпізнати капчу, що складається з великих літер будь-якої мови? Ні, не зможе. Програма бере список символів, що використовуються для розпізнавання, з конфігураційних файлів, що знаходяться в \ Program Files \ Foundstone Free Tools \ TesserCap 1.0 \ tessdata \ configs. Поясню на прикладі: якщо ми вибрали опції Numerics і Lower Case, то програма звернеться до файлу lowernumeric, що починається з параметра tessedit char whitelist. За ним слідує список символів, які будуть використовуватися для вирішення капчи. За замовчуванням в файлах містяться тільки букви латинського алфавіту, так що для розпізнавання кирилиці треба замінити або доповнити список символів. Тепер трохи про те, для чого потрібно поле Http Request Headers. Наприклад, на деяких веб-сайтах потрібно залогінитися, для того щоб побачити капчу. Щоб TesserCap змогла отримати доступ до капчі, програмі необхідно передати в запиті HTTP такі заголовки, як Accept, Cookie і Referrer і т. Д. Використовуючи веб-проксі (Fiddler, Burp, Charles, WebScarab, Paros і т. Д.), Можна перехопити їх посилають заголовки запиту і ввести їх в поле введення Http Request Headers. Ще одна опція, яка напевно стане в нагоді, - це Follow Redirects. Справа в тому, що TesserCap за замовчуванням не слід переадресації. Якщо тестовий URL-адресу повинен слідувати переадресації для отримання зображення, потрібно вибрати цю опцію. Ну і залишилася остання опція, що включає / відключає механізм попередньої обробки зображень, який ми розглянемо далі. За замовчуванням попередня обробка зображень відключена. Користувачі спочатку налаштовують фільтри попередньої обробки зображень згідно тестованим CAPTCHA-зображень і потім активують цей модуль. Все CAPTCHA-зображення, що завантажуються після включення опції Enable Image Preprocessing, проходять попередню обробку і вже потім передаються в OCR-систему Tesseract для вилучення тексту.Інтерфейс. Вкладка Image Preprocessing
Ну ось ми і дісталися до найцікавішої вкладки. Саме тут настроюються фільтри для видалення з капч різних шумів і розмитості, які намагаються максимально ускладнити завдання системі розпізнавання. Процес настройки універсального фільтра гранично простий і складається з дев'яти етапів. На кожному етапі попередньої обробки зображення його зміни відображаються. Крім того, на сторінці є компонент перевірки, який дозволяє оцінити правильність розпізнавання капчі при накладеному фільтрі. Розглянемо докладніше кожен етап. Етап 1. Інверсія кольоруНа даному етапі інвертуються кольору пікселів для CAPTCHA-зображень. Код, представлений нижче, демонструє, як це відбувається: for (each pixel in CAPTCHA) (if (invertRed is true) new red = 255 - current red if (invertBlue is true) new blue = 255 - current blue if (invertGreen is true ) new green = 255 - current green) Інверсія одного або декількох кольорів часто відкриває нові можливості для перевірки тестованого CAPTCHA-зображення. Етап 2. Зміна кольоруНа даному етапі можна змінити колірні компоненти для всіх пікселів зображення. Кожне числове поле може містити 257 (від 1 до 255) можливих значень. Для RGB-компонентів кожного пікселя в залежності від значення в поле діє таким чином:- Якщо значення дорівнює -1, відповідний колірний компонент не змінюється.
- Якщо значення не дорівнює -1, всі знайдені компоненти зазначеного кольору (червоний, зелений або синій) змінюються відповідно до введеного в поля значенням. Значення 0 видаляє компонент, значення 255 встановлює його максимальну інтенсивність і т. Д.
- Average -> (Red + Green + Blue) / 3.
- Human -> (0.21 * Red + 0.71 * Green + 0.07 * Blue).
- Average of minimum and maximum color components -> (Minimum (Red + Green + Blue) + Maximum (Red + Green + Blue)) / 2.
- Minimum -> Minimum (Red + Green + Blue).
- Maximum -> Maximum (Red + Green + Blue).
 Етап 4. Згладжування і різкістьЩоб ускладнити витяг тексту з CAPTCHA-зображень, в них додають шум у формі однопіксельні або многопіксельних точок, сторонніх ліній і просторових спотворень. При згладжуванні зображення зростає випадковий шум, для усунення якого потім використовуються фільтри Bucket або Cutoff. У числовому полі Passes слід вказати, скільки разів потрібно застосувати відповідну маску зображення перед переходом на наступний етап. Давай розглянемо компоненти фільтра для згладжування і підвищення різкості. Доступні два типи масок зображення:
Етап 4. Згладжування і різкістьЩоб ускладнити витяг тексту з CAPTCHA-зображень, в них додають шум у формі однопіксельні або многопіксельних точок, сторонніх ліній і просторових спотворень. При згладжуванні зображення зростає випадковий шум, для усунення якого потім використовуються фільтри Bucket або Cutoff. У числовому полі Passes слід вказати, скільки разів потрібно застосувати відповідну маску зображення перед переходом на наступний етап. Давай розглянемо компоненти фільтра для згладжування і підвищення різкості. Доступні два типи масок зображення: - Фіксовані маски. За замовчуванням TesserCap має шість найбільш популярних масок зображення. Ці маски можуть згладжувати зображення або підвищувати різкість (перетворення Лапласа). Зміни відображаються відразу ж після вибору маски за допомогою відповідних кнопок.
- Призначені для користувача маски зображення. Користувач також може налаштувати призначені для користувача маски обробки зображень, вводячи значення в числові поля і натискаючи кнопку Save Mask. якщо сума коефіцієнтів в цих віконцях менше нуля, видається помилка і маска не застосовується. При виборі фіксованою маски кнопку Save Mask використовувати не потрібно.
- Залишити без зміни (Leave As Is).
- Замінити білим (White).
- Замінити чорним (Black).
розпізнаємо капчи
Ну що ж, мабуть, ми розглянули всі опції цієї утиліти, і тепер непогано було б протестувати якусь капчу на міцність .. Результат аналізу капчи сайт з попередньою
Результат аналізу капчи сайт з попередньою обробкою зображень. Судячи з результатів, фільтр
підібрати не вдалося Отже, запускаємо утиліту і йдемо на сайт журналу. Бачимо список свіжих новин, заходимо в першу-ліпшу і прокрутити до місця, де можна залишити свій коментар. Ага, коммент так просто не додати (ще б, а то б давно вже все заспамілі) - потрібно вводити капчу. Ну що ж, перевіримо, чи можна це автоматизувати. Копіюємо URL картинки і вставляємо його в адресний рядок TesserCap. Зазначаємо, що потрібно завантажити 12 капч, і натискаємо Start. Програма слухняно завантажила 12 картинок і спробувала їх розпізнати. На жаль, все капчи виявилися або не розпізнані, про що свідчить напис -Failed- під ними, або розпізнані неправильно. Загалом, не дивно, так як сторонні шуми і спотворення не були видалені. Цим ми зараз і займемося. Тиснемо правою кнопкою миші на одну з 12 завантажених картинок і відправляємо її в систему попередньої обробки (Send To Image Preprocessor). Уважно розглянувши всі 12 капч, бачимо, що вони містять тільки цифри, тому йдемо на вкладку опцій і вказуємо, що розпізнавати потрібно тільки цифри (Character Set = Numerics). Тепер можна переходити на вкладку Image Preprocessing для налаштування фільтрів. Відразу скажу, що пограти з першими трьома фільтрами ( «Інверсія кольору», «Зміна кольору», «Градація сірого») я не побачив жодного позитивного ефекту, тому залишив там все по дефолту. Я вибрав маску Smooth Mask 2 і встановив кількість проходів рівним одному. Фільтр Grayscale buckets я пропустив і перейшов відразу до налаштування відсікання. Вибрав значення 154 і вказав, що ті пікселі, яких менше, потрібно встановити в 0, а ті, яких більше, в 255. Щоб позбутися від решти точок, включив chopping і змінив ширину кордону до 10. Останній фільтр включати не було сенсу, тому я відразу натиснув на Solve. На капчі у мене було число 714945, але програма розпізнала його як 711435. Це, як бачиш, зовсім невірно. В кінцевому підсумку, як я не бився, нормально розпізнати капчу у мене так і не вийшло. Довелося експериментувати з pastebin.com, які без проблем вдалося розпізнати. Але якщо ти опинишся терплячі і терплячими і зумієш отримати коректне розпізнавання капч з сайт, то відразу заходь на вкладку опцій і включай попередню обробку зображень (Enable Image Preprocessing). Потім переходь на Main і, клікнувши на Start, завантажуй свіжу порцію капч, які тепер будуть попередньо оброблятися твоїм фільтром. Після того, як програма відпрацює, відзнач коректно / некоректно розпізнані капчи (кнопки Mark as Correct / Mark as InCorrect). З цього моменту можна поглядати зведену статистику по розпізнаванню за допомогою Show Statistics. В общем-то, це своєрідний звіт про захищеність тій чи іншій CAPTCHA. Якщо стоїть питання про вибір того чи іншого рішення, то за допомогою TesserCap цілком можна провести своє власне тестування.
Результат перевірки CAPTCHA на популярних сайтах
Веб-сайт і частка розпізнаних капч:- Wikipedia> 20-30%
- Ebay> 20-30%
- reddit.com> 20-30%
- CNBC> 50%
- foodnetwork.com> 80-90%
- dailymail.co.uk> 30%
- megaupload.com> 80%
- pastebin.com> 70-80%
- cavenue.com> 80%
висновок
CAPTCHA-зображення є одним з найефективніших механізмів щодо захисту веб-додатків від автоматизованого заповнення форм. Однак слабкі капчи зможуть захистити від випадкових роботів і не встоять перед цілеспрямованими спробами їх вирішити. Як і криптографічні алгоритми, CAPTCHA-зображення, ретельно протестовані і забезпечують високий рівеньбезпеки, є самим найкращим способомзахисту. На основі статистики, яку привів автор програми, я вибрав для своїх проектів reCaptcha і буду рекомендувати її всім своїм друзям - вона виявилося найстійкішою з протестованих. У будь-якому випадку не варто забувати, що в Мережі є чимало сервісів, які пропонують напівавтоматизованого рішення CAPTCHA. Через спеціальний API ти передаєш сервісу зображення, а той через нетривалий час повертає рішення. Вирішує капчу реальна людина (наприклад, з Китаю), отримуючи за це свою копієчку. Тут вже ніякого захисту немає. 🙂Саме так називалася робота, представлена мною на Балтійському науково-інженерному конкурсі, і принесла мені чарівну папірець з римської одиничкою, а також новенький ноутбук.
Робота полягала в розпізнаванні CAPTCHA, що використовуються великими операторами стільникового зв'язкув формах відправки SMS, і демонстрації недостатню ефективність застосовуваного ними підходу. Щоб не зачіпати нічию гордість, будемо називати цих операторів алегорично: червоний, жовтий, зелений і синій.
Проект отримав офіційну назву Captchureі неофіційне Breaking Defective Security Measures. Будь-які збіги випадкові.
Як не дивно, все (ну, майже все) ці CAPTCHA виявилися досить слабкими. Найменший результат - 20% - належить жовтому оператору, найбільший - 86% - синього. Таким чином, я вважаю, що завдання «демонстрації неефективності» була успішно вирішена.
Причини вибору саме стільникових операторів тривіальні. Шановному Науковому Журі я розповідав байку про те, що « стільникові операторимають достатньо грошей, щоб найняти програміста будь-якої кваліфікації, і, в той же час, їм необхідно мінімізувати кількість спаму; таким чином, їх CAPTCHA повинні бути досить потужними, що, як показує моє дослідження, зовсім не так ». Насправді ж все було набагато простіше. Я хотів набратися досвіду, зламавши розпізнавши якусь просту CAPTCHA, і вибрав жертвою CAPTCHA червоного оператора. А вже після цього, заднім числом народилася вищезгадана історія.
Отже, ближче до тіла. Ніякого мегапродвінутого алгоритму для розпізнавання усіх чотирьох видів CAPTCHA у мене немає; замість нього я написав 4 різних алгоритму для кожного виду CAPTCHA окремо. Однак, незважаючи на те, що алгоритми в деталях різні, в цілому вони виявилися дуже схожими.
Як і багато авторів до мене, я розбив завдання розпізнавання CAPTCHA на 3 підзадачі: попередню обробку (препроцесс), сегментацію і розпізнавання. На етапі препроцесса з вихідного зображення видаляються різні шуми, спотворення і ін. В сегментації з вихідного зображення виділяються окремі символи і проводиться з постобработка (наприклад, зворотний поворот). При розпізнаванні символи по одному обробляються попередньо навченої нейромережею.
Істотно розрізнявся тільки препроцесс. Це пов'язано з тим, що в різних CAPTCHA застосовуються різні методи спотворення зображень, відповідно, і алгоритми для видалення цих спотворень сильно розрізняються. Сегментація експлуатувала ключову ідею пошуку компонентів зв'язності з незначними наворотами (значними їх довелося зробити тільки у жовто-смугастих). Розпізнавання було абсолютно однаковим у трьох операторів з чотирьох - знову-таки, відрізнявся тільки жовтий оператор.
Нарешті, білим закрашуються дрібні (менше 10px) чорні зв'язкові області:
Іноді (рідко, але буває) буква розпадається на кілька частин; для виправлення цього прикрого непорозуміння я застосовую досить просту евристику, що оцінює належність кількох компонентів зв'язності до одного символу. Ця оцінка залежить тільки від горизонтального положення і розмірів описують прямокутників (bounding boxes) кожного символу.
Неважко помітити, що багато символів виявилися об'єднані в один компонент зв'язності, в зв'язку з чим треба їх розділяти. Тут на допомогу приходить той факт, що на зображенні завжди рівно 5 символів. Це дозволяє з великою точністю обчислювати, скільки символів знаходиться в кожному знайденому компоненті.
Для пояснення принципу роботи такого алгоритму доведеться трохи заглибитися в матчастину. Позначимо кількість знайдених сегментів за n, а масив ширини ( правильно сказав, да?) Всіх сегментів за widths [n]. Будемо вважати, що якщо після вищезазначених етапів n> 5, зображення розпізнати не вдалося. Розглянемо всі можливі розкладання числа 5 на цілі позитивні складові. Їх небагато - всього 16. Кожне таке розкладання є певною можливої розстановки символів по знайденим компонентів зв'язності. Логічно припустити, що чим ширше вийшов сегмент, тим більше символів він містить. З усіх розкладів п'ятірки виберемо тільки ті, в яких кількість доданків одно n. Поділимо кожен елемент з widths на widths - як би нормалізуємо їх. Те ж саме проробимо з усіма залишилися розкладаннями - поділимо кожне число в них на перший доданок. А тепер (увага, кульмінація!) Зауважимо, що отримані впорядковані n-ки можна мислити як точки в n-вимірному просторі. З урахуванням цього, знайдемо найближчим по Евклиду розкладання п'ятірки до нормалізовано widths. Це і є шуканий результат.
До речі, в зв'язку з цим алгоритмом мені в голову прийшов ще один цікавий спосіб шукати все розкладання числа на складові, який я, правда, так і не реалізував, закопавшись в пітоновскіх структурах даних. Коротко - він досить очевидно вилазить, якщо зауважити, що кількість розкладів певної довжини збігається з відповідним рівнем трикутника Паскаля. Втім, я впевнений, що цей алгоритм давним-давно відомий.
Так ось, після визначення кількості символів в кожному компоненті наступає інша евристика - ми вважаємо, що роздільники між символами тонше, ніж самі символи. Для того щоб скористатися цим таємним знанням, розставимо по сегменту n-1 роздільників, де n - кількість символів в сегменті, після чого в невеликій околиці кожного роздільник порахуємо проекцію зображення вниз. В результаті цього проектування ми отримаємо інформацію про те, скільки в кожному стовпці пікселів належать символам. Нарешті, в кожній проекції знайдемо мінімум і зрушимо роздільник туди, після чого пошматував зображення за цими розділювачам.
Нарешті, розпізнавання. Як я вже говорив, для нього я застосовую нейросеть. Для її навчання спочатку я виганяю дві сотні зображень під загальним заголовком trainsetчерез вже написані і налагоджені перші два етапи, в результаті чого отримую папку з великою кількістю акуратно нарізаних сегментів. Потім, руками вичищаю сміття (результати неправильної сегментації, наприклад), після чого результат привожу до одного розміру і віддаю на розтерзання FANN. На виході отримую навчену нейросеть, яка і використовується для розпізнавання. Ця схема дала збій тільки один раз - але про це пізніше.
В результаті на тестовому наборі (який я використав для навчання, кодове ім'я - testset) З 100 картинок були правильно розпізнані 45. Чи не занадто високий результат - його, звичайно, можна поліпшити, наприклад, уточнивши препроцесс або переробивши розпізнавання, але, чесно кажучи, мені було лінь з цим возитися.
Крім того, я використовував ще один критерій оцінки продуктивності алгоритму - середня помилка. Обчислювався він у такий спосіб. Для кожного зображення знаходилося відстань Левенштейна між думкою алгоритму про це зображенні і правильною відповіддю - після чого бралося середнє арифметичне по всіх зображень. Для цього виду CAPTCHA середня помилка склала 0.75 символу / зображення. Мені здається, що це більш точний критерій, ніж просто відсоток розпізнавання.
До речі кажучи, майже всюди (крім жовтого оператора) у мене використовувалася саме така схема - 200 картинок в trainset, 100 - в testset.
Green
Наступною метою я вибрав зелених - хотілося взятися за щось більш серйозне, ніж підбір матриці спотворень.
переваги:
- ефект тривимірності
- Поворот і зміщення
- нерівномірне яскравість
недоліки:
- Символи помітно темніше фону
- Верхню сторону прямокутника добре видно - можна використовувати для зворотного повороту
Виявилося, що навіть незважаючи на те, що ці недоліки, здавалося б, незначні, їх експлуатація дозволяє досить ефективно розправитися з усіма перевагами.
Знову почнемо з попередньої обробки. Спочатку оцінимо кут повороту прямокутника, на якому лежать символи. Для цього застосуємо до вихідного зображення оператор Erode (пошук локального мінімуму), потім Threshold, щоб виділити залишки прямокутника і, нарешті, інверсію. Отримаємо симпатичне біла пляма на чорному тлі.
Далі починається глибока думка. Перше. Для оцінки кута повороту всього прямокутника досить оцінити кут повороту його зверху. Друге. Можна оцінити кут повороту верхньої сторони пошуком прямий, паралельної цій стороні. Третє. Для опису будь-якої прямої, крім строго вертикальної, достатньо двох параметрів - зміщення по вертикалі від центру координат і кута нахилу, причому нас цікавить тільки другий. Четверте. Завдання пошуку прямий можна вирішити не дуже великим перебором - занадто великих кутів повороту там не буває, та й надвисока точність нам не потрібна. П'яте. Для пошуку необхідної прямої можна зіставити кожної прямої оцінку того, наскільки вона близька до шуканої, після чого вибрати максимум. Шосте. Найважливіше. Щоб оцінити деякий кут нахилу прямої, уявімо, що зображення зверху стосується пряма з таким кутом нахилу. Зрозуміло, що з розмірів зображення і кута нахилу можна однозначно обчислити зміщення прямої по вертикалі, так що вона задається однозначно. Далі, поступово будемо рухати цю пряму вниз. У якийсь момент вона торкнеться білої плями. Запам'ятаємо цей момент і площа перетину прямої з плямою. Нагадаю, що пряма має 8ми-зв'язний на площині, тому гнівні вигуки із залу про те, що пряма має один вимір, а площа - поняття двовимірне, тут недоречні. Потім, ще деякий час будемо рухати цю пряму вниз, на кожному кроці запам'ятовуючи площа перетину, після чого підсумуємо отримані результати. Ця сума і буде оцінкою даного кута повороту.
Підводячи підсумок вищесказаного: будемо шукати таку пряму, що при русі її вниз по зображенню яскравість пікселів, що лежать на цій прямій, зростає найбільш різко.
Отже, кут повороту знайдений. Але не слід поспішати відразу застосувати отримане знання. Справа в тому, що це іспоріт зв'язність зображення, а вона нам ще знадобиться.
Наступний крок - відділення символів від фону. Тут нам дуже допоможе той факт, що символи значно темніше фону. Цілком логічний крок з боку розробників - інакше картинку було б дуже складно прочитати. Хто не вірить - може спробувати самостійно бінаризованими зображення і переконатися на власні очі.
Однак, підхід «в лоб» - спроба відсікти символи пороговим перетворенням - тут не працює. Найкращий результат, якого мені вдалося домогтися - при t = 140 - виглядає вельми плачевно. Залишається дуже багато сміття. Тому довелося застосувати обхідний шлях. Ідея тут наступна. Символи, як правило, зв'язні. Причому їм часто належать найтемніші точки на зображенні. А що якщо спробувати застосувати заливку з цих найтемніших точок, а потім викинути занадто маленькі залиті області - очевидний сміття?
Результат, чесно кажучи, є вражаючим. На більшості зображень вдається позбутися від фону повністю. Втім, буває, що символ розпадається на кілька частин - в цьому випадку може допомогти один милицю в сегментації - але про це трохи пізніше.
Нарешті, комбінація операторів Dilate і Erode позбавляє нас від дрібних дірок, що залишилися в символах, що допомагає спростити розпізнавання.
Сегментація тут значно простіше, ніж препроцесс. В першу чергу шукаємо компоненти зв'язності.
Потім, об'єднуємо близькі по горизонталі компоненти (процедура рівно та ж, що і раніше):
Цей алгоритм дозволив досягти результату в 69% успішно розпізнаних зображень і отримати середню помилку 0.3 символу / зображення.
Blue
Отже, третім статус «defeated» отримав синій оператор. Це була, так би мовити, перепочинок перед дійсно великою рибою ...
Тут складно щось записати в гідності, але я, все ж, спробую:
- Поворот символів - єдине більш-менш серйозна перешкода
- Фоновий шум у вигляді символів
- Символи іноді торкаються один одного
На противагу цьому:
- Фон значне світліше символів
- Символи добре вписуються в прямокутник
- Різний колір символів дозволяє легко відокремлювати їх один від одного
Отже, препроцесс. Почнемо з відсікання фону. Оскільки зображення триколірні, поріжемо його на канали, а потім викинемо всі крапки, які яскравіше 116 по всіх каналах. Отримаємо ось таку симпатичну маску:
Потім, перетворимо зображення в колірний простір HSV (Вікіпедія). Це збереже інформацію про колір символів, а заодно і прибере градієнт з їх країв.
Застосуємо до результату отриману раніше маску:
На цьому препроцесс закінчується. Сегментація також вельми тривіальна. Почнемо, як завжди, з компонентів зв'язності:
Можна було б на цьому і зупинитися, але так виходить всього 73%, що мене зовсім не влаштовує - всього на 4% краще, ніж результат свідомо більш складної CAPTCHA. Отже, наступним кроком буде зворотний поворот символів. Тут нам стане в нагоді вже згаданий мною факт про те, що місцеві символи добре вписуються в прямокутник. Ідея полягає в тому, щоб знайти прямокутник для кожного символу, а потім по його нахилу обчислити нахил власне символу. Тут під описує прямокутником розуміється такий, що він, по-перше, містить в собі всі пікселі даного символу, а, по-друге, має найменшу площу з усіх можливих. Я користуюся готової реалізацією алгоритму пошуку такого прямокутника з OpenCV (MinAreaRect2).
Цей алгоритм успішно розпізнає 86% зображень при середній помилку в 0.16 символу / зображення, що підтверджує припущення про те, що ця CAPTCHA - дійсно найпростіша. Втім, і оператор не найбільший ...
Yellow
Настає найцікавіше. Так би мовити, апофеоз моєї творчої діяльності 🙂 Ця CAPTCHA - дійсно найскладніша як для комп'ютера, так і, на жаль для людини.
переваги:
- Шум у вигляді плям і ліній
- Поворот і масштабування символів
- Близьке розташування символів
недоліки:
- Дуже обмежена палітра
- Всі лінії дуже тонкі
- Плями часто не перетинаються з символами
- Кут повороту всіх символів приблизно однаковий
Над першим кроком я думав довго. Перше, що приходило в голову - погратися з локальними максимумами (Dilate), щоб видалити невеликий шум. Однак, такий підхід призводив до того, що і від букв мало що залишалося - лише рвані обриси. Проблема ускладнювалася тим, що текстура самих символів неоднорідна - це добре видно при великому збільшенні. Щоб від неї позбутися, я вирішив вибрати самий тупий спосіб - відкрив Paint і записав коди всіх кольорів, що зустрічаються в зображеннях. Виявилося, що всього в цих зображеннях зустрічаються чотири різних текстури, причому на три з них припадає по 4 різних кольори, а на останню - 3; більш того, всі компоненти цих квітів виявилися кратними 51. Далі я склав таблицю кольорів, за допомогою якої вдалося позбутися від текстури. Втім, перед цим «ремапом» я ще затирають всі занадто світлі пікселі, які зазвичай знаходяться по краях символів - інакше доводиться позначати їх як шум, а потім з ними боротися, в той час як інформації в них міститься небагато.
Отже, після цього перетворення на зображенні знаходиться не більше 6 кольорів - 4 кольори символів (будемо їх умовно називати сірим, синім, світло-зеленим і темно-зеленим), білий (колір фону) і «невідомий», що позначає, що колір пікселя на його місці не вдалося ототожнити ні з одним з відомих кольорів. Називати умовно - тому що до цього моменту я рятуюся від трьох каналів і переходжу до звичного і зручного монохромному зображенню.
Наступним кроком стало очищення зображення від ліній. Тут ситуацію рятує той факт, що ці лінії дуже тонкі - всього 1 піксель. Напрошується простий фільтр: пройтися по всьому зображенню, порівнюючи колір кожного пікселя з квітами його сусідів (парами - по вертикалі і горизонталі); якщо сусіди за кольором збігаються, і при цьому не збігаються з кольором самого пікселя - зробити його таким же, як і сусіди. Я застосовую трохи більше навороченную версію того ж фільтра, який працює в два етапи. На першому він оцінює сусідів на відстані 2, на другому - на відстані 1. Це дозволяє домогтися ось такого ефекту:
Далі я рятуюся від більшості плям, а також від «невідомого» кольору. Для цього я спочатку шукаю все дрібні зв'язкові області (менші 15 по площі, якщо бути точним), наношу їх на чорно-білу маску, після чого результат поєдную з областями, зайнятими «невідомим» кольором.
За допомогою цих масок я нацьковують алгоритм Inpaint (а точніше, його реалізацію в OpenCV). Це дозволяє досить ефективно вичистити більшу частину сміття з зображення.
Однак, реалізація цього алгоритму у OpenCV була створена для роботи з фотографіями і відео, а не розпізнавання штучно створених зображень з зашумлений текстом. Після його застосування з'являються градієнти, чого хотілося б уникнути, щоб спростити сегментацію. Таким чином, доводиться виробляти додаткову обробку, а саме - підвищення різкості. Для кольору кожного пікселя я обчислюю найближчий до нього з вищезгаданої таблиці (нагадаю, там 5 кольорів - по одному на кожну з текстур символів і білий).
Нарешті, останнім кроком препроцесса буде видалення всіх залишилися дрібних зв'язкових областей. З'являються вони після застосування Inpaint, тому ніякого повторення тут немає.
Переходимо до сегментації. Її сильно ускладнює той факт, що символи знаходяться дуже близько один до одного. Може трапитися така ситуація, що за одним символом не видно половину іншого. Зовсім погано стає, коли ці символи ще й одного кольору. Крім того, залишки сміття також грають свою роль - може статися так, що на оригінальному документі лінії в великій кількостіперетиналися в одному місці. У цьому випадку той алгоритм, який я описав раніше, виявиться нездатним від них позбутися.
Після тижня, проведеного в марних спробах написати сегментацію так само, як і в попередніх випадках, я забив на цю справу і змінив тактику. Моя нова стратегія полягала в тому, щоб розділити весь процес сегментації на дві частини. У першій оцінюється кут повороту символів і виконується зворотний поворот. У другій з уже розгорнутого зображення заново виділяються символи. Отже, приступимо. Почнемо, як завжди, з пошуку компонентів зв'язності.
Потім потрібно оцінити кут повороту кожного символу. Ще під час роботи з оператором-фанатом-Грінпісу я придумав алгоритм для цього, але написав і застосував його тільки тут. Для того щоб проілюструвати його роботу, проведу аналогію. Уявіть собі поршень, який рухається на чорно-біле зображення символу від низу до верху. Ручка поршня, за яку його штовхають, розташована вертикально, робоча площадка, якої він штовхає - горизонтально, паралельно нижній частині зображення і перпендикулярно ручці. Ручка прикріплена до майданчика посередині, і в місці приєднання знаходиться рухливе зчленування, в результаті чого майданчик може повертатися. Хай вибачать мене фахівці з термінології.
Нехай ручка рухається вгору, штовхаючи перед собою майданчик по законам фізики. Будемо вважати, що матеріальним є тільки біле зображення символу, а крізь чорний фон поршень з легкістю проходить. Тоді поршень, дійшовши до білого кольору, почне з ним взаємодіяти, а саме, повертатися - за умови, що сила до ручки все ще прикладається. Зупинитися він може в двох випадках: якщо він уперся в символ по обидві сторони від точки прикладання сили, або якщо він уперся в символ самої точкою прикладання сили. У всіх інших випадках він зможе продовжувати рух. Увага, кульмінація: будемо вважати, що кут повороту символу - це кут нахилу поршня в той момент, коли він зупинився.
Цей алгоритм досить точний, але свідомо занадто великі результати (більше 27 градусів) я не враховую. З решти я знаходжу середнє арифметичне, після чого цілком все зображення повертаю на мінус цей кут. Потім виконую пошук компонентів зв'язності ще раз.
Далі стає все цікавіше і цікавіше. У попередніх прикладах я починав різні махінації з отриманими сегментами, після чого передавав їх нейромережі. Тут все інакше. Перш за все, для того щоб хоча б частково відновити інформацію, втрачену після поділу зображення на компоненти зв'язності, я на кожному з них темно-сірим кольором (96) домальовую «фон» - то, що було поруч з вирізаним сегментом, але в нього не потрапило , після чого згладжую обриси символів, застосовуючи ту ж процедуру, що і в препроцессе для ліній (з відстанню до сусіда, рівним одиниці).
Формально (з точки зору модулів програми) тут сегментація закінчується. Уважний читач, мабуть, помітив, що ніде не згадувалося поділ злиплих символів. Так, це так - на розпізнавання я їх передаю саме в такому вигляді, а допілівать вже на місці.
Причина полягає в тому, що той метод поділу злиплих символів, який був описаний раніше (з найменшою проекцією) тут не працює - шрифт обраний авторами вельми вдало. Тому доводиться застосовувати інший, більш складний підхід. В основі цього підходу лежить ідея, що нейросеть можна використовувати для сегментації.
На самому початку я описував алгоритм, що дозволяє знайти кількість символів в сегменті при відомий ширині цього сегмента і загальній кількості символів. Цей же алгоритм використовується і тут. Для кожного сегмента обчислюється кількість символів в ньому. Якщо він там один - нічого допілівать не потрібно, і цей сегмент відразу відправляється >> = в нейросеть. Якщо ж символ там не один, то уздовж сегмента на рівних відстанях розставляються потенційні роздільники. Потім кожен роздільник рухається в своїй невеликій околиці, і попутно обчислюється реакція нейромережі на символи біля цього роздільник, після чого залишається лише вибрати максимум (насправді, там все це робить досить тупий алгоритм, але, в принципі, все дійсно приблизно так).
Природно, участь нейромережі в процесі сегментації (або досегментаціі, якщо завгодно) виключає можливість використовувати ту схему навчання нейромережі, яку я вже описував. Якщо точніше, він не дозволяє отримати найпершу нейросеть - для навчання інших може використовуватися вона. Тому я роблю досить просто - використовую звичайні методи сегментації (проекція) для навчання нейромережі, в той час як при її використанні в роботу вступає вищеописаний алгоритм.
Є ще одна тонкість, пов'язана з використанням нейромережі в цьому алгоритмі. У попередніх прикладах нейросеть навчалася на майже необроблених результатах препроцесса і сегментації. Тут це дозволяло отримати не більше 12% успішного розпізнавання. Мене це категорично не влаштовувало. Тому, перш ніж починати чергову епоху навчання нейромережі, я вносив в вихідні зображення різні спотворень, грубо моделюють реальні: додати білих / сірих / чорних крапок, сірих ліній / кіл / прямокутників, повернути. Також я збільшив trainset з 200 зображень до 300 і додав так званий validsetдля перевірки якості навчання під час навчання на 100 зображень. Це дозволило добитися збільшення продуктивності десь відсотків на п'ять, а вкупі з сегментацією нейромережею якраз і дало той результат, про який я говорив на початку статті.
Надання статистики ускладнене тим, що у мене в підсумку вийшло двінейромережі: одна давала більший відсоток розпізнавання, а інша - меншу помилку. Тут я привожу результати першої.
Всього, як я вже говорив неодноразово, в testset налічувалося 100 зображень. З них успішно розпізнано було 20, невдало, відповідно, 80, а помилка склала 1.91 символу на зображення. Помітно гірше, ніж у всіх інших операторів, а й CAPTCHA відповідна.
замість висновку
Все, що відноситься до цієї роботи, я виклав в спеціальній гілці форуму на своєму сайті, зокрема: вихідний код, Netsukuku). У той же час, хочеться чогось, що, по-перше, можливо зробити за рік (хоча б удвох), і по-друге, серйозно претендувало б на високе місце на тому ж ISEF. Може бути, ви зможете підказати, в якому напрямку мені слід рухатися?
Більшість людей не в курсі, але моєї дисертацією була програма для читання тексту з зображення. Я думав, що, якщо зможу отримати високий рівень розпізнавання, то це можна буде використовувати для поліпшення результатів пошуку. Мій відмінний радник доктор Гао Джунбін запропонував мені написати дисертацію на цю тему. Нарешті я знайшов час написати цю статтю і тут я спробую розповісти про все те, що дізнався. Якби тільки було щось подібне, коли я тільки починав ...
Як я вже говорив, я намагався взяти звичайні зображення з інтернету і витягати з них текст для поліпшення результатів пошуку. Більшість моїх ідей було засновано на методах злому капчі. Як всім відомо, капча - це ті самі всіх подразнюючу штуки, на кшталт «Введіть літери, які ви бачите на зображенні» на сторінках реєстрації або зворотного зв'язку.
Капча влаштована так, що людина може прочитати текст без праці, в той час, як машина - немає (привіт, reCaptcha!). На практиці це ніколи не працювало, т. К. Майже кожну капчу, яку розміщували на сайті зламували протягом декількох місяців.
У мене непогано виходило - понад 60% зображень було успішно розгадано з моєї невеликої колекції. Досить непогано, враховуючи кількість різноманітних зображень в інтернеті.
При своєму дослідженні я не знайшов ніяких матеріалів, які допомогли б мені. Так, статті є, але в них опубліковані дуже прості алгоритми. Насправді я знайшов кілька неробочих прикладів на PHP і Perl, взяв з них кілька фрагментів і отримав непогані результати для дуже простий капчи. Але жоден з них мені особливо не допоміг, т. К. Це було занадто просто. Я з тих людей, які можуть читати теорію, але нічого не зрозуміти без реальних прикладів. А в більшості статей писалося, що вони не будуть публікувати код, т. К. Бояться, що його будуть використовувати в поганих цілях. Особисто я думаю, що капча - це марна трата часу, т. К. Її досить легко обійти, якщо знати як.
Власне через відсутність якихось матеріалів, що показують злом капчи для початківців я і написав цю статтю.
Давайте почнемо. Ось список того, що я збираюся висвітлити в цій статті:
- використовувані технології
- Що таке капча
- Розпізнавання зображення з використанням ІІ
- навчання
- Збираємо всі разом
- Результати та висновки
використовувані технології
Всі приклади написані на Python 2.5 з використанням бібліотеки PIL. Повинно працювати і в Python 2.6.
Встановіть їх в зазначеному вище порядку і ви готові до запуску прикладів.
відступ
У прикладах я буду жорстко ставити безліч значень прямо в коді. У мене немає мети створити універсальний распознаватель капч, а тільки показати як це робиться.
Капча, що це таке врешті-решт?
В основному капча є приклад одностороннього перетворення. Ви можете легко взяти набір символів і отримати з нього капчу, але не навпаки. Інша тонкість - вона повинна бути проста для читання людиною, але не піддаватися машинному розпізнавання. Капча може розглядатися як простий тест типу «Ви людина?». В основному вони реалізуються як зображення з якимись символами або словами.
Вони використовуються для запобігання спаму на багатьох інтернет-сайтах. Наприклад, капчу можна знайти на сторінці реєстрації в Windows Live ID.
Вам показують зображення, і, якщо ви дійсно людина, то вам потрібно ввести його текст в окреме поле. Здається непоганою ідеєю, яка може захистити вас від тисяч автоматичних реєстрацій з метою спаму або розповсюдження віагри на вашому форумі? Проблема в тому, що ІІ, а зокрема методи розпізнавання зображень зазнали значних змін і стають дуже ефективними в певних областях. OCR (оптичне розпізнавання символів) в наші дні є досить точним і легко розпізнає друкований текст. Було прийнято рішення додати трохи кольору і ліній, щоб утруднити роботу комп'ютера без якихось незручностей для користувачів. Це свого роду гонка озброєнь і як зазвичай на будь-який захист придумують більш сильна зброя. Перемогти посилену капчу складніше, але все одно можливо. Плюс до всього зображення повинно залишатися досить простим, щоб не викликати роздратування у звичайних людей.
Це зображення є прикладом капчи, яку ми будемо розшифровувати. Це реальна капча, яка розміщена на реальному сайті.
Це досить проста капча, яка складається з символів однакового кольору і розміру на білому тлі з деяким шумом (пікселі, кольору, лінії). Ви думаєте, що цей шум на задньому плані ускладнить розпізнавання, але я покажу, як його легко видалити. Хоч це і не дуже сильна капча, але вона є хорошим прикладом для нашої програми.
Як знайти і витягти текст із зображень
Існує багато методів для визначення положення тексту на зображенні і його вилучення. За допомогою Google ви можете знайти тисячі статей, які пояснюють нові методи і алгоритми для пошуку тексту.
Для цього прикладу я буду використовувати витяг кольору. Це досить проста техніка, за допомогою якої я отримав досить непогані результати. Саме цю техніку я використовував для своєї дисертації.
Для наших прикладів я буду використовувати алгоритм багатозначного розкладання зображення. По суті, це означає, що ми спочатку побудуємо гістограму кольорів зображення. Це робиться шляхом отримання всіх пікселів в зображенні з угрупованням за кольором, після чого проводиться підрахунок по кожній групі. Якщо подивитися на нашу тестову капчу, то можна побачити три основні кольори:
- Білий фон)
- Сірий (шум)
- Червоний (текст)
На Python це буде виглядати дуже просто.
Наступний код відкриває зображення, перетворює його в GIF (полегшує нам роботу, т. К. В ньому всього 255 кольорів) з друкує гистограмму квітів.
From PIL import Image im = Image.open ( "captcha.gif") im = im.convert ( "P") print im.histogram ()
У підсумку ми отримаємо наступне:
Тут ми видем кількість пікселів кожного з 255 кольорів в зображенні. Ви можете побачити, що білий (255, найостанніший) зустрічається найчастіше. За ним йде червоний (текст). Щоб переконатися в цьому, напишемо невеликий скрипт:
From PIL import Image from operator import itemgetter im = Image.open ( "captcha.gif") im = im.convert ( "P") his = im.histogram () values = () for i in range (256): values [i] = his [i] for j, k in sorted (values.items (), key = itemgetter (1), reverse = True) [: 10]: print j, k
І отримуємо такі дані:
Це список з 10 найбільш поширених квітів в зображенні. Як очікувалося, білий повторюється найчастіше. Потім йдуть сірий і червоний.
Як тільки ми отримали цю інформацію, ми створюємо нові зображення, засновані на цих колірних групах. Для кожного з найбільш поширених квітів ми створюємо нове бінарне зображення (з 2 кольорів), де пікселі цього кольору заповнюється чорним, а все інше білим.
Червоний у нас став третім серед найбільш поширених квітів і це означає, що ми хочемо зберегти групу пікселів з кольором 220. Коли я експериментував я виявив, що колір 220 досить близький до 220, так що ми збережемо і цю групу пікселів. Наведений нижче код відкриває капчу, перетворює її в GIF, створює нове зображення такого ж розміру з білим фоном, а потім обходить оригінальне зображення в пошуках потрібного нам кольору. Якщо він знаходить піксель з потрібним нам кольором, то він зазначає цей же піксель на другому зображенні чорним кольором. Перед завершенням роботи друге зображення зберігається.
From PIL import Image im = Image.open ( "captcha.gif") im = im.convert ( "P") im2 = Image.new ( "P", im.size, 255) im = im.convert ( "P ") temp = () for x in range (im.size): for y in range (im.size): pix = im.getpixel ((y, x)) temp = pix if pix == 220 or pix == 227: # these are the numbers to get im2.putpixel ((y, x), 0) im2.save ( "output.gif")
Запуск цього фрагмента коду дає нам наступний результат.
На зображенні ви можете побачити, що у нас успішно вийшло витягти текст з фону. Щоб автоматизувати цей процес ви можете поєднати перший і другий скрипт.
Чую, як питаєте: «А що, якщо на капчі текст написаний різними кольорами?». Так, наша техніка все ще зможе працювати. Припустімо, що найбільш поширений колір - це колір фону і тоді ви зможете знайти кольору символів.
Таким чином, на даний моментми успішно витягли текст з зображення. Наступним кроком буде визначення того, чи містить зображення текст. Я поки не буду писати тут код, т. К. Це зробить розуміння складним, в той час як сам алгоритм досить простий.
For each binary image: for each pixel in the binary image: if the pixel is on: if any pixel we have seen before is next to it: add to the same set else: add to a new set
На виході у вас буде набір кордонів символів. Тоді все, що вам потрібно буде зробити - це порівняти їх між собою і подивитися, чи йдуть вони послідовно. Якщо так, то вам випав джек-пот і ви правильно визначили символи, що йдуть поруч. Ви так само можете перевіряти розміри отриманих областей або просто створювати нове зображення і показувати його (метод show () у зображення), щоб переконатися в точності алгоритму.
From PIL import Image im = Image.open ( "captcha.gif") im = im.convert ( "P") im2 = Image.new ( "P", im.size, 255) im = im.convert ( "P ") temp = () for x in range (im.size): for y in range (im.size): pix = im.getpixel ((y, x)) temp = pix if pix == 220 or pix == 227: # these are the numbers to get im2.putpixel ((y, x), 0) # new code starts here inletter = False foundletter = False start = 0 end = 0 letters = for y in range (im2.size): # slice across for x in range (im2.size): # slice down pix = im2.getpixel ((y, x)) if pix! = 255: inletter = True if foundletter == False and inletter == True: foundletter = True start = y if foundletter == True and inletter == False: foundletter = False end = y letters.append ((start, end)) inletter = False print letters
В результаті у нас виходило наступне:
[(6, 14), (15, 25), (27, 35), (37, 46), (48, 56), (57, 67)]
Це позиції по горизонталі початку і кінця кожного символу.
ІІ і векторний простір при розпізнаванні образів
Розпізнавання зображень можна вважати найбільшим успіхом сучасного ІІ, що дозволило йому потрапити в усі види комерційних додатків. Прекрасним прикладом цього є поштові індекси. Насправді у багатьох країнах вони читаються автоматично, т. К. Навчити комп'ютер розпізнавати номери досить просте завдання. Це може бути не очевидно, але розпізнавання образів вважається проблемою ІІ, хоч і дуже вузькоспеціалізованою.
Ледь не першою річчю, з якою стикаються при знайомстві з іноземними інвестиціями в розпізнаванні образів є нейронні мережі. Особисто я ніколи не мав успіху з нейронними мережами при розпізнаванні символів. Я зазвичай навчаю його 3-4 символам, після чого точність падає так низько, що вона була б на порядок вище, відгадувати я символи випадковим чином. Спочатку це викликало у мене легку паніку, т. К. Це було тим самим недостатньому ланкою в моєї дисертації. На щастя, нещодавно я прочитав статтю про vector-space пошукових системах і порахував їх альтернативним методом класифікації даних. Врешті-решт вони опинилися кращому вибором, т. К.
- Вони не вимагають великого вивчення
- Ви можете додавати / видаляти неправильні дані і відразу бачити результат
- Їх легше зрозуміти і запрограмувати
- Вони забезпечують класифіковані результати, таким чином ви зможете бачити топ X збігів
- Чи не можете щось розпізнати? Додайте це і ви зможете разпознать це моментально, навіть якщо воно повністю відрізняється від чогось поміченого раніше.
Звичайно, безкоштовного сиру не буває. Головний недолік в швидкості. Вони можуть бути набагато повільніше нейронних мереж. Але я думаю, що їх плюси все ж переважують цей недолік.
Якщо хочете зрозуміти, як працює векторний простір, то раджу почитати Vector Space Search Engine Theory. Це найкраще, що я знайшов для початківців.
Я побудував своє розпізнавання зображень на основі вищезгаданого документа і це було першою річчю, яку я спробував написати на улюбленому ЯП, який я в цей час вивчав. Прочитайте цей документ і як ви зрозумієте його суть - повертайтеся сюди.
Вже повернулися? Добре. Тепер ми повинні запрограмувати наше векторний простір. На щастя, це зовсім не складно. Приступимо.
Import math class VectorCompare: def magnitude (self, concordance): total = 0 for word, count in concordance.iteritems (): total + = count ** 2 return math.sqrt (total) def relation (self, concordance1, concordance2) : relevance = 0 topvalue = 0 for word, count in concordance1.iteritems (): if concordance2.has_key (word): topvalue + = count * concordance2 return topvalue / (self.magnitude (concordance1) * self.magnitude (concordance2))
Це реалізація векторного простору на Python в 15 рядків. По суті воно просто приймає 2 словника і видає число від 0 до 1, яке вказує як вони пов'язані. 0 означає, що вони не пов'язані, а 1, що вони ідентичні.
навчання
Наступне, що нам потрібно - це набір зображень, з якими ми будемо порівнювати наші символи. Нам потрібно навчальну множину. Це безліч може бути використано для навчання будь-якого роду ІІ, який ми будемо використовувати (нейронні мережі і т. Д.).
Дані, що використовуються можуть бути доленосними для успішності розпізнавання. Чим краще дані, тим більше шансів на успіх. Так як ми плануємо розпізнавати конкретну капчу і вже можемо витягти з неї символи, то чому б не використати їх в якості навчальної множини?
Це я і зробив. Я скачав багато згенерованих капч і моя програма розбила їх на літери. Тоді я зібрав отримані зображення в колекції (групи). Після декількох спроб у мене було принаймні один приклад кожного символу, які генерувала капча. Додавання більшої кількості прикладів підвищить точність розпізнавання, але мені вистачило і цього для підтвердження моєї теорії.
From PIL import Image import hashlib import time im = Image.open ( "captcha.gif") im2 = Image.new ( "P", im.size, 255) im = im.convert ( "P") temp = () print im.histogram () for x in range (im.size): for y in range (im.size): pix = im.getpixel ((y, x)) temp = pix if pix == 220 or pix == 227: # these are the numbers to get im2.putpixel ((y, x), 0) inletter = False foundletter = False start = 0 end = 0 letters = for y in range (im2.size): # slice across for x in range (im2.size): # slice down pix = im2.getpixel ((y, x)) if pix! = 255: inletter = True if foundletter == False and inletter == True: foundletter = True start = y if foundletter == True and inletter == False: foundletter = False end = y letters.append ((start, end)) inletter = False # New code is here. We just extract each image and save it to disk with # what is hopefully a unique name count = 0 for letter in letters: m = hashlib.md5 () im3 = im2.crop ((letter, 0, letter, im2.size) ) m.update ( "% s% s"% (time.time (), count)) im3.save ( "./% s.gif"% (m.hexdigest ())) count + = 1
На виході ми отримуємо набір зображень в цій же директорії. Кожному з них присвоюється унікальних хеш на випадок, якщо ви будете обробляти кілька капч.
Ось результат цього коду для нашої тестової капчи:
Ви самі вирішуєте, як зберігати ці зображення, але я просто помістив їх в директорії з тим же ім'ям, що знаходиться на зображенні (символ або цифра).
Збираємо всі разом
Останній крок. У нас є ізвлеканіе тексту, ізвлеканіе символів, техніка розпізнавання і навчальну множину.
Ми отримуємо зображення капчі, виділяємо текст, отримуємо символи, а потім порівнювання їх з нашим навчальним безліччю. Ви можете завантажити остаточну програму з навчальним безліччю і невеликою кількістю капч за цим посиланням.
Тут ми просто завантажуємо навчальну множину, щоб мати можливість порівнювати з ним:
Def buildvector (im): d1 = () count = 0 for i in im.getdata (): d1 = i count + = 1 return d1 v = VectorCompare () iconset = [ "0", "1", "2" , "3", "4", "5", "6", "7", "8", "9", "0", "a", "b", "c", "d", " e "," f "," g "," h "," i "," j "," k "," l "," m "," n "," o "," p "," q " , "r", "s", "t", "u", "v", "w", "x", "y", "z"] imageset = for letter in iconset: for img in os.listdir ( "./iconset/%s/"%(letter)): temp = if img! =" Thumbs.db ": temp.append (buildvector (Image.open (" ./ iconset /% s /% s "% (letter, img)))) imageset.append ((letter: temp))
А тут уже відбувається все чарівництво. Ми визначаємо, де знаходиться кожен символ і перевіряємо його за допомогою нашого векторного простору. Потім сортуємо результати і друкуємо їх.
Count = 0 for letter in letters: m = hashlib.md5 () im3 = im2.crop ((letter, 0, letter, im2.size)) guess = for image in imageset: for x, y in image.iteritems (): if len (y)! = 0: guess.append ((v.relation (y, buildvector (im3)), x)) guess.sort (reverse = True) print "", guess count + = 1
висновки
Тепер у нас є все, що потрібно і ми можемо спробувати запустити нашу диво-машину.
Вхідний файл - captcha.gif. Очікуваний результат: 7s9t9j
Python crack.py (0.96376811594202894, "7") (0.96234028545977002, "s") (0.9286884286888929, "9") (0.98350370609844473, "t") (0.96751165072506273, "9") (0.96989711688772628, "j")
Тут ми видем передбачуваний символ і ступінь впевненості в тому, що це дійсно він (від 0 до 1).
Схоже, що у нас дійсно все вийшло!
Насправді на тестових капч даний скрипт буде видавати успішний результат приблизно в 22% випадків.
Python crack_test.py Correct Guesses - 11.0 Wrong Guesses - 37.0 Percentage Correct - 22.9166666667 Percentage Wrong - 77.0833333333
Більшість невірних результатів доводиться на неправильне распознаваіне цифри «0» і букви «О». Немає нічого несподіваного, т. К. Навіть люди їх часто плутають. У нас ще є проблема з розбиванням на символи, але це можна вирішити просто перевіривши результат розбиття і знайшовши золоту середину.
Однак, навіть з таким не дуже досконалим алгоритмом ми можемо розгадувати кожну п'яту капчу за такий час, де людина не встигла б розгадати і одну.
Виконання цього коду на Core 2 Duo E6550 дає наступні результати:
Real 0m5.750s user 0m0.015s sys 0m0.000s
У нашому каталозі знаходиться 48 капч, з чого випливає, що на розгадування однієї йде приблизно 0.12 секунд. З нашими 22% відсотками успішного розгадування ми можемо розгадувати близько 432 000 капч в день і отримувати 95 040 правильних результатів. А якщо використовувати багатопоточність?
От і все. Сподіваюся, що мій досвід буде використаний вами в хороших цілях. Я знаю, що ви можете використовувати цей код на шкоду, але щоб зробити дійсно щось небезпечне ви повинні досить сильно його змінити.
Для тих, хто намагається захистити себе капчі я можу сказати, що це вам не сильно допоможе, т. К. Їх можна обійти програмно або просто платити іншим людям, які будуть розгадувати їх вручну. Подумайте над іншими способами захисту.