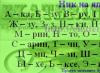Синтаксис регулярних виразів є досить складним і його вивчення вимагає серйозних зусиль. Найкращим посібником з регулярним виразом на сьогоднішній день є книга Дж. Фрідл "Регулярні вирази", що дозволяє, за словами автора, "навчитися мислити регулярними виразами".
Основні поняття
Регулярний вираз (regular expression)- засіб для обробки рядків або послідовність символів, що визначає шаблон тексту.
модифікатор- призначений для "інструктування" регулярного виразу.
метасимволи- спеціальні символи, які служать командами мови регулярних виразів.
Регулярний вираз задається як звичайна змінна, тільки замість лапок використовується слеш, наприклад: var reg = / рег_вираженіе /
Під найпростішими шаблонами будемо розуміти такі шаблони, які не потребують будь-яких спеціальних символах.
Припустимо, нашим завданням є заміна всіх букв "р" (малих і великих) на латинську велику букву "R" в словосполученні Регулярні вирази.
створюємо шаблон var reg = / р /і воспользуясь методом replaceздійснюємо задумане
В результаті отримаємо рядок - РегуляRние вираження, Заміна відбулася лише на першому входженні букви "р" з урахуванням регістру.
Але під умови нашого завдання цей результат не підходить ... Тут нам знадобляться модифікатори"G" і "i", які можуть використовуватися як окремо, так і спільно. Ці модифікатори ставляться в кінці шаблону регулярного виразу, після слеша, і мають таке значення:
модифікатор"G" - задає пошук в рядку як "глобальний", тобто в нашому випадку заміна відбудеться для всіх входжень літери "р". Тепер шаблон виглядає так: var reg = / р / g, Підставивши його в наш код
отримаємо рядок - РегуляRние виRаженія.
модифікатор "i"- задає пошук в рядку без урахування регістру, додавши цей модифікатор в наш шаблон var reg = / р / gi, Після виконання скрипта одержимо шуканий результат нашого завдання - RегуляRние виRаженія.
Спеціальні символи (метасимволи)
Метасимволи задають тип символів шуканого рядка, спосіб оточення шуканої рядка в тексті, а так само кількість символів окремого типу в просматриваемом тексті. Тому метасимволи можна розділити на три групи:
- Метасимволи пошуку збігів.
- Кількісні метасимволи.
- Метасимволи позиціонування.
Метасимволи пошуку збігів
значення | опис | ||
межа слова | задає умову, при якому шаблон повинен виконуватися на початку або кінці слова | / \ Ber /Зівпадає з error, Не збігається з heroабо з player |
|
не кордони слова | задає умову, при якому шаблон не виконується на початку або кінці слова | / \ Ber /Зівпадає з heroабо з player, Не збігається з error |
|
цифра від 0 до 9 | / \ D \ d \ d \ d /збігається з будь-яким чотирьох значним числом |
||
/ \ D \ D \ D \ D /не відповідатиме 2005 або 05.габо №126 і т.д. |
|||
одиночний порожній символ | відповідає символу пробілу | \ Over \ sbyte \збігається тільки з over byte |
|
одиночний непорожній символ | будь-який один символ за винятком пробілу | \ Over \ Sbyte \Зівпадає з over-byteабо з over_byte, Не збігається з over byteабо over - byte |
|
буква, цифра або символ підкреслення | / A \ w /Зівпадає з A1або з AB, Не збігається з A + |
||
не буква, цифра або символ підкреслення | / A \ W /не збігається з A1або з AB, Зівпадає з A + |
||
будь-який символ | будь-які знаки, букви, цифри і т.д. | /.../ збігається з будь-якими трьома символами ABCабо [Email protected] або 1 q |
|
набір символів | задає умову, при якому шаблон повинен виконуватися при будь-якому збігу символів увязнених в квадратні дужки | / WERTY /Зівпадає з QWERTY, з AWERTY |
|
набір не входять символів | задає умову, при якому шаблон не повинен виконуватися при будь-якому збігу символів увязнених в квадратні дужки | / [^ QA] WERTY /не збігається з QWERTY, з AWERTY |
Символи, наведені в таблиці "Метасимволи пошуку збігів" не треба плутати з послідовністю знаків переходу використовуваних в рядках, таких як \\ t - табуляція, \\ n - перехід на новий рядок і т.д.
кількісні метасимволи
кількість збігів | ||
Нуль і більшу кількість разів | / Ja * vaScript /Зівпадає з JvaScriptабо з JaavaScriptабо з JaaavaScript, Не збігається з JovaScript |
|
Нуль або один раз | / Ja? VaScript /збігається тільки з JvaScriptабо з JavaScript |
|
Один і більшу кількість разів | / Ja + vaScript /Зівпадає з JavaScriptабо з JaavaScriptабо з JaaavaScript, Не збігається з JvaScript |
|
точно n разів | / Ja (2) vaScript /збігається тільки з JaavaScript |
|
n або більшу кількість разів | / Ja (2,) vaScript /Зівпадає з JaavaScriptабо з JaaavaScript, Не збігається з JvaScriptабо з JavaScript |
|
по крайней мере, n раз, але не більше ніж m разів | / Ja (2,3) vaScript /збігається тільки з JaavaScriptабо з JaaavaScript |
Кожен символ, наведений в таблиці "Кількісні метасимволи" застосовується до одного попереднього символу або метасимвол в регулярному виразі.
метасимволи позиціонування
Останній набір метасимволов призначений для позначення, де шукати (якщо це важливо) підрядок на початку рядка або в кінці.
Деякі методи для роботи з шаблонами
replace- даний метод ми вже використали на самому початку статті, він призначений для пошуку зразка і заміни знайденої підрядка на нову підрядок.
exec- даний метод виконує зіставлення рядка із зразком, заданим шаблоном. Якщо зіставлення зі зразком закінчилося невдачею, то повертається значення null. В іншому випадку результатом є масив підрядків, відповідних заданому зразку. / * Перший елемент масиву дорівнюватиме вихідної рядку задовольняє заданим шаблоном * /
наприклад:
в результаті отримаємо чотири рядки:
Дата народження: 15.09.1980
День народження: 15
Місяць народження: 09
Рік народження: 1980
висновок
У статті відображено далеко не всі можливості і принади регулярних виразів, для більш глибокого вивчення цього питання пораджу вивчити об'єкт RegExp. Так само хочу звернути увагу на те, що синтаксис регулярних виразів не чим не відрізняється як в JavaScript, так і в PHP. Наприклад, для перевірки правильності введення e-mail, регулярний вираз, що для JavaScript, що для PHP буде виглядати однаково /[Email protected]+. (2,3) / i.
модифікатори
Символ «мінус» (-) Меред модифікатором (за винятком U) створює його заперечення.
спецсимволи
| аналог | опис | |
|---|---|---|
| () | подмаскі, вкладене вираз | |
| груповий символ | ||
| (A, b) | кількість входжень від «a» до «b» | |
| | | логічне «або», у випадку з односимвольних альтернативами використовуйте | |
| \ | екранування спец символу | |
| . | будь-який сиволов, крім перекладу рядки | |
| \ d | десяткова цифра | |
| \ D | [^ \ D] | будь-який символ, крім десяткової цифри |
| \ f | кінець (розрив) сторінки | |
| \ n | переклад рядка | |
| \ pL | буква в кодуванні UTF-8 при використанні модифікатора u | |
| \ r | повернення каретки | |
| \ s | [\ T \ v \ r \ n \ f] | символ пробілу |
| \ S | [^ \ S] | будь-який символ, крім промельного |
| \ t | табуляція | |
| \ w | будь-яка цифра, буква або знак підкреслення | |
| \ W | [^ \ W] | будь-який символ, крім цифри, букви або знака підкреслення |
| \ v | вертикальна табуляція |
Спецсимволи всередині символьного класу
Позиція всередині рядка
| приклад | відповідність | опис | |
|---|---|---|---|
| ^ | ^ a | a aa aaa | початок рядка |
| $ | a $ | aaa aa a | кінець рядка |
| \ A | \ Aa | a aa aaa aaa aaa | початок тексту |
| \ z | a \ z | aaa aaa aaa aa a | кінець тексту |
| \ b | a \ b \ ba | aa a aa a a aa a aa | межа слова, твердження: попередній символ словесний, а наступний - ні, або навпаки |
| \ B | \ Ba \ B | a a a a a a | відсутність кордону слова |
| \ G | \ Ga | aaa aaa | Попередній успішний пошук, пошук зупинився на 4-й позиції - там, де не знайшлося a |
якоря
Якоря в регулярних виразах вказують на початок або кінець чого-небудь. Наприклад, рядки або слова. Вони представлені певними символами. Наприклад, шаблон, відповідний рядку, що починається з цифри, повинен мати такий вигляд:
Тут символ ^ позначає початок рядка. Без нього шаблон відповідав би будь-якому рядку, що містить цифру.
Символьні класи
Символьні класи в регулярних виразах відповідають відразу деякого набору символів. Наприклад, \ d відповідає будь цифрі від 0 до 9 включно, \ w відповідає буквах і цифрам, а \ W - всім символам, крім букв і цифр. Шаблон, що ідентифікує букви, цифри і пробіл, виглядає так:
POSIX
POSIX - це відносно нове доповнення сімейства регулярних виразів. Ідея, як і в випадку з символьними класами, полягає в використанні скорочень, що представляють деяку групу символів.
твердження
Спочатку практично у всіх виникають труднощі з розумінням тверджень, проте познайомившись з ними ближче, ви будете використовувати їх досить часто. Твердження надають спосіб сказати: «я хочу знайти в цьому документі кожне слово, яке включає букву" q ", за якою не слід" werty "».
[^ \ S] * q (?! Werty) [^ \ s] *
Наведений вище код починається з пошуку будь-яких символів, крім пробілу ([^ \ s] *), за якими слід q. Потім парсер досягає «смотрящего вперед» твердження. Це автоматично робить попередній елемент (символ, групу або символьний клас) умовним - він буде відповідати шаблоном, тільки якщо твердження вірне. У нашому випадку, твердження є негативним (?!), Т. Е. Воно буде вірним, якщо те, що в ньому шукається, що не буде знайдено.
Отже, парсер перевіряє кілька наступних символів по запропонованим шаблоном (werty). Якщо вони знайдені, то твердження помилкове, а значить символ q буде «проігнорований», т. Е. Не буде відповідати шаблоном. Якщо ж werty, не знайдено, то твердження вірне, і з q все в порядку. Потім триває пошук будь-яких символів, крім пробілу ([^ \ s] *).
квантори
Квантори дозволяють визначити частину шаблону, яка повинна повторюватися кілька разів поспіль. Наприклад, якщо ви хочете з'ясувати, чи містить документ рядок з від 10 до 20 (включно) букв «a», то можна використовувати цей шаблон:
A (10,20)
За замовчуванням квантори - «жадібні». Тому квантор +, що означає «один або більше разів», буде відповідати максимально можливому значенню. Іноді це викликає проблеми, і тоді ви можете сказати квантору перестати бути жадібним (стати «ледачим»), використовуючи спеціальний модифікатор. Подивіться на цей код:
".*"Цей шаблон відповідає тексту, укладеним в подвійні лапки. Однак, ваша вихідна рядок може бути на кшталт цієї:
Привіт світ
Наведений вище шаблон знайде в цьому рядку ось таку подстроку:
"Helloworld.htm" title = "(! LANG: Привіт, Світ" !}
Він виявився занадто жадібним, захопивши найбільший шматок тексту, який зміг.
".*?"Цей шаблон також відповідає будь-яким символам, укладеними в подвійні лапки. Але лінива версія (зверніть увагу на модифікатор?) Шукає найменшу з можливих входжень, і тому знайде кожну подстроку в подвійних лапках окремо:
"Helloworld.htm" "Привіт, Мир"
Екранування в регулярних виразах
Регулярні вирази використовують деякі символи для позначення різних частин шаблону. Однак, виникає проблема, якщо вам потрібно знайти один з таких символів в рядку, як звичайний символ. Точка, наприклад, в регулярному виразі означає «будь-який символ, крім розриву рядків». Якщо вам потрібно знайти точку в рядку, ви не можете просто використовувати «. »Як шаблон - це призведе до знаходження практично всього. Отже, вам необхідно повідомити парсеру, що ця точка повинна вважатися звичайною точкою, а не «будь-яким символом». Це робиться за допомогою знака екранування.
Знак екранування, що передує символу на кшталт точки, змушує парсер ігнорувати його функцію і вважати звичайним символом. Є кілька символів, які потребують такого захисту, в більшості шаблонів і мов. Ви можете знайти їх в правому нижньому кутку шпаргалки ( «Мета-символи»).
Шаблон для знаходження точки такий:
\.Інші спеціальні символи в регулярних виразах відповідають незвичайним елементам в тексті. Перенесення рядка і табуляції, наприклад, можуть бути набрані з клавіатури, але ймовірно зіб'ють з пантелику мови програмування. Знак екранування використовується тут для того, щоб повідомити парсеру про необхідність вважати наступний символ спеціальним, а не звичайною літерою або цифрою.
Спецсимволи екранування в регулярних виразах
підстановка рядків
Підстановка рядків докладно описана в наступному параграфі «Групи і діапазони», однак тут слід згадати про існування «пасивних» груп. Це групи, ігноровані при підстановці, що дуже корисно, якщо ви хочете використовувати в шаблоні умова «або», але не хочете, щоб ця група брала участь в підстановці.
Групи і діапазони
Групи і діапазони дуже-дуже корисні. Ймовірно, простіше буде почати з діапазонів. Вони дозволяють вказати набір відповідних символів. Наприклад, щоб перевірити, чи містить рядок шістнадцятиричні цифри (від 0 до 9 і від A до F), слід використовувати такий діапазон:
Щоб перевірити зворотне, використовуйте негативний діапазон, який в нашому випадку підходить під будь-який символ, крім цифр від 0 до 9 і букв від A до F:
[^ A-Fa-f0-9]
Групи найбільш часто застосовуються, коли в шаблоні необхідно умова «або»; коли потрібно послатися на частину шаблону з іншої його частини; а також при підстановці рядків.
Використовувати «або» дуже просто: наступний шаблон шукає «ab» або «bc»:
Якщо в регулярному виразі необхідно послатися на якусь із попередніх груп, слід використовувати \ n, де замість n підставити номер потрібної групи. Вам може знадобитися шаблон, відповідний буквах «aaa» або «bbb», за якими слід число, а потім ті ж три букви. Такий шаблон реалізується за допомогою груп:
(Aaa | bbb) + \ 1
Перша частина шаблону шукає «aaa» або «bbb», об'єднуючи знайдені букви в групу. Далі йде пошук однієї або більше цифр (+), і нарешті \ 1. Остання частина шаблону посилається на першу групу і шукає те ж саме. Вона шукає збіг з текстом, вже знайденим першою частиною шаблону, а не відповідне йому. Таким чином, «aaa123bbb" не буде задовольняти вищенаведеного шаблоном, так як \ 1 шукатиме «aaa» після числа.
Одним з найбільш корисних інструментівв регулярних виразах є підстановка рядків. При заміні тексту можна послатися на знайдену групу, використовуючи $ n. Скажімо, ви хочете виділити в тексті всі слова «wish» жирним шрифтом. Для цього вам слід використовувати функцію заміни по регулярному виразу, яка може виглядати так:
Replace (pattern, replacement, subject)
Першим параметром буде приблизно такою шаблон (можливо вам знадобляться кілька додаткових символів для цієї конкретної функції):
([^ A-Za-z0-9]) (wish) ([^ A-Za-z0-9])
Він знайде будь-які входження слова «wish» разом з попереднім і наступним символами, якщо тільки це не букви або цифри. Тоді ваша підстановка може бути такою:
$1$2$3
Нею буде замінена вся знайдена за шаблоном рядок. Ми починаємо заміну з першого знайденого символу (який не буква і не цифра), відзначаючи його $ 1. Без цього ми б просто видалили цей символ з тексту. Те ж стосується кінця підстановки ($ 3). В середину ми додали HTML тегдля жирного накреслення (зрозуміло, замість нього ви можете використовувати CSS або ), Виділивши їм другу групу, знайдену за шаблоном ($ 2).
модифікатори шаблонів
Модифікатори шаблонів використовуються в декількох мовах, зокрема, в Perl. Вони дозволяють змінити роботу парсеру. Наприклад, модифікатор i змушує парсер ігнорувати регістри.
Регулярні вирази в Perl обрамляются одним і тим же символом на початку і в кінці. Це може бути будь-який символ (частіше використовується «/»), і виглядає все таким чином:
/ Pattern /
Модифікатори додаються в кінець цього рядка, ось так:
/ Pattern / i
Мета-символи
Нарешті, остання частина таблиці містить мета-символи. Це символи, що мають спеціальне значення в регулярних виразах. Так що якщо ви хочете використовувати один з них як звичайний символ, то його необхідно екранувати. Для перевірки наявності дужки в тексті, використовується такий шаблон:
Шпаргалка являє собою загальне керівництво по шаблонах регулярних виразів без урахування специфіки будь-якої мови. Вона представлена у вигляді таблиці, що міститься на одному друкованому аркуші формату A4. Створена під ліцензією Creative Commons на базі шпаргалки, автором якої є Dave Child. Завантажити в PDF, PNG.
JavaScript regexp - це тип об'єкта, який використовується для зіставлення послідовності символів в рядках.
Створюємо перше регулярне вираз
Існує два способи створення регулярного виразу: з використанням литерала регулярного виразу або за допомогою конструктора регулярних виразів. Кожен з них представляє один і той же шаблон: символ « c», За яким слід« a», А потім символ« t».
// літерал регулярного виразу полягає в Слеш (/) var option1 = / cat /; // Конструктор регулярнго вираження var option2 = new RegExp ( "cat");
Як правило, якщо регулярний вираз залишається константою, тобто не буде змінюватися, краще використовувати буквальний регулярного виразу. Якщо воно буде змінюватися або залежить від інших змінних, краще використовувати метод з конструктором.
Метод RegExp.prototype.test ()
Пам'ятаєте, я казав, що регулярні вирази є об'єктами? Це означає, що у них є ряд методів. Найпростіший метод - це JavaScript regexp test, Який повертає логічне значення:
True (істина): рядок містить шаблон регулярного виразу.
False (брехня): збіги не знайдено.
console.log (/cat/.test ( "the cat says meow")); // вірно console.log (/cat/.test ( "the dog says bark")); // невірно
Пам'ятка з основ регулярних виразів
Секрет регулярних виразів полягає в запам'ятовуванні типових символів і груп. Я настійно рекомендую витратити кілька годин на таблицю, наведену нижче, а потім повернутися, і продовжити вивчення.
символи
- . - (точка) відповідає будь-якому одиночному символу за винятком перенесення рядка;
- * - відповідає попередньому висловом, яке повторюється 0 або більше разів;
- + - відповідає попередньому висловом, яке повторюється 1 або більше разів;
- ? - попередній вираз є необов'язковим ( відповідає 0 або 1 раз);
- ^ - відповідає початку рядка;
- $ - відповідає кінцю рядка.
Групи символів
- d- відповідає будь-якому одиночному цифровому символу.
- w- відповідає будь-якому символу (цифри, букви або знаку підкреслення).
- [XYZ]- набір символів. Відповідає будь-якому одиночному символу з набору, заданого в дужках. Також можна задавати і діапазони символів, наприклад, .
- [XYZ] +- відповідає символу з набору, повторюваного один або більше разів.
- [^A -Z]- всередині набору символів «^» використовується як знак заперечення. В даному прикладі шаблону відповідає все, що не є буквами у верхньому регістрі.
прапори:
В JavaScript regexp існує п'ять необов'язкових прапорів. Вони можуть використовуватися окремо або разом, і розміщуються після закриває слеша. Наприклад: / [ A -Z] / g. Тут я приведу тільки два прапора.
g- глобальний пошук.
i- пошук, нечутливий до регістру.
додаткові конструкції
(x)- захоплюючі дужки. Цей вислів відповідає x і запам'ятовує це відповідність, тому їм можна скористатися пізніше.
(?:x)- незахвативающіе дужки. Вираз відповідає x, але не запам'ятовує це відповідність.
Відповідає x, тільки якщо за ним слід y.
Протестуємо вивчений матеріал
Спочатку протестуємо все вище сказане. Припустимо, що ми хочемо перевірити рядок на наявність будь-яких цифр. Для цього можна використовувати конструкцію «d».
console.log (/d/.test ( "12-34")); // вірно
Наведений вище код повертає значення true, якщо в рядку є хоча б одна цифра. Що робити, якщо потрібно перевірити рядок на відповідність формату? Можна використовувати декілька символів «d», щоб визначити формат:
console.log (/dd-dd/.test ( "12-34")); // вірно console.log (/dd-dd/.test ( "тисячі двісті тридцять чотири")); // невірно
Якщо неважливо, як в JavaScript regexp online йдуть цифри до і після знака «-», можна використовувати символ «+», щоб показати, що шаблон «d» зустрічається один або кілька разів:
console.log (/ d + -d + /. test ( "12-34")); // вірно console.log (/ d + -d + /. Test ( "1-234")); // вірно console.log (/ d + -d + /. Test ( "- 34")); // невірно
Для простоти можна використовувати дужки, щоб згрупувати вираження. Припустимо, у нас є нявкання кішки, і ми хочемо перевірити відповідність шаблону « meow»(Мяу):
console.log (/ me + (ow) + w / .test ( "meeeeowowoww")); // вірно
Тепер давайте розберемося.
m => відповідність одній букві 'm';
e + => відповідність букві «e» один або кілька разів;
(Ow) + => відповідність буквах «ow» один або кілька разів;
w => відповідність букві 'w';
'M' + 'eeee' + 'owowow' + 'w'.
Коли оператори типу «+» використовуються відразу після дужок, вони впливають на весь вміст дужок.
Оператор «? ». Він вказує, що попередній символ є необов'язковим. Як ви побачите нижче, обидва тестових прикладу повертають значення true, тому що символи «s» позначені як необов'язкові.
console.log (/ cats? says? /i.test ( "the Cat says meow")); // вірно console.log (/ cats? Says? /I.test ( "the Cats say meow")); // вірно
Якщо ви захочете знайти символ слеша, потрібно екранізувати його за допомогою зворотного слеша. Те ж саме вірно для інших символів, які мають особливе значення, наприклад, знаку питання. Ось JavaScript regexp приклад того, як їх шукати:
var slashSearch = ///; var questionSearch = /? /;
- d- це те ж саме, що і: кожна конструкція відповідає цифровому символу.
- w- це те ж саме, що [ A -Za -z 0-9_]: Обидва вирази відповідають будь-якому одиночному алфавітно-цифровому символу або підкреслення.
Приклад: додаємо прогалини в рядки, написані в «верблюжому» стилі
У цьому прикладі ми дуже втомилися від «верблюжого» стилю написання і нам потрібен спосіб додати пропуски між словами. Ось приклад:
removeCc ( "camelCase") // => повинен повернути "camel Case"
Існує просте рішення з використанням регулярного виразу. По-перше, нам потрібно знайти всі заголовні букви. Це можна зробити за допомогою пошуку набору символів і глобального модифікатора.
Це відповідає символу «C» в «camelCase»
Тепер, як додати пробіл перед «C»?
Нам потрібно використовувати захоплюючі дужки! Вони дозволяють знайти відповідність і запам'ятати його, щоб використовувати пізніше! Використовуйте захоплюючі дужки, щоб запам'ятати знайдену велику літеру:
Отримати доступ до захопленого значенням пізніше можна так:
Вище ми використовуємо $ 1 для доступу до захопленого значенням. До речі, якби у нас було два набори захоплюючих дужок, ми використовували б $ 1 і $ 2 для посилання на захоплені значення і аналогічно для більшої кількості захоплюючих дужок.
Якщо вам потрібно використовувати дужки, але не потрібно фіксувати це значення, можна використовувати незахвативающіе дужки: (?: X). В цьому випадку знаходиться відповідність x, але воно не запам'ятовується.
Повернемося до поточної задачі. Як ми реалізуємо захоплюючі дужки? За допомогою методу JavaScript regexp replace! В якості другого аргументу ми передаємо «$ 1». Тут важливо використовувати лапки.
function removeCc (str) (return str.replace (/ () / g, "$ 1");)
Знову подивимося на код. Ми захоплюємо прописну букву, а потім замінюємо її тієї ж самої буквою. Усередині лапок вставимо пробіл, за яким слідує змінна $ 1. У підсумку отримуємо пробіл після кожної великої літери.
function removeCc (str) (return str.replace (/ () / g, "$ 1");) removeCc ( "camelCase") // "camel Case" removeCc ( "helloWorldItIsMe") // "hello World It Is Me"
Приклад: видаляємо великі літери
Тепер у нас є рядок з купою непотрібних великих літер. Ви здогадалися, як їх видалити? По-перше, нам потрібно вибрати усі великі літери. Потім використовуємо пошук набору символів за допомогою глобального модифікатора:
Ми знову будемо використовувати метод replace, але як в цей раз зробити рядкової символ?
function lowerCase (str) (return str.replace (// g, ???);)
Підказка: в методі replace () в якості другого параметра можна вказати функцію.
Ми будемо використовувати стрелочную функцію, щоб не захоплювати значення знайденого збіги. При використанні функції в методі JavaScript regexp replace ця функція буде викликана після пошуку збігів, і результат функції використовується в якості замісної рядки. Ще краще, якщо збіг є глобальним і знайдено кілька збігів - функція буде викликана для кожного знайденого збіги.
function lowerCase (str) (return str.replace (// g, (u) => u.toLowerCase ());) lowerCase ( "camel Case") // "camel case" lowerCase ( "hello World It Is Me" ) // "hello world it is me"
The RegExp constructor creates a regular expression object for matching text with a pattern.
For an introduction to regular expressions, read the Regular Expressions chapter in the JavaScript Guide.
The source for this interactive example is stored in a GitHub repository. If you "d like to contribute to the interactive examples project, please clone https://github.com/mdn/interactive-examples and send us a pull request.
Syntax
Literal, constructor, and factory notations are possible:
/ Pattern / flags new RegExp (pattern [, flags]) RegExp (pattern [, flags])
Parameters
pattern The text of the regular expression; or as of ES5, another RegExp object or literal (for the two RegExp constructor notations only). Patterns can include so they can match a wider range of values than would a literal string. flagsIf specified, flags is a string that contains the flags to add; or if an object is supplied for the pattern, the flags string will replace any of that object "s flags (and lastIndex will be reset to 0) (as of ES2015). If flags is not specified and a regular expressions object is supplied, that object "s flags (and lastIndex value) will be copied over.
flags may contain any combination of the following characters:
G global match; find all matches rather than stopping after the first match. i ignore case; if u flag is also enabled, use Unicode case folding. m multiline; treat beginning and end characters (^ and $) as working over multiple lines (i.e., match the beginning or end of each line (delimited by \ n or \ r), not only the very beginning or end of the whole input string). s "dotAll"; allows. to match newlines. u Unicode; treat pattern as a sequence of Unicode code points. (See also Binary strings). y sticky; matches only from the index indicated by the lastIndex property of this regular expression in the target string (and does not attempt to match from any later indexes).
Description
There are two ways to create a RegExp object: a literal notation and a constructor.
- The literal notation "s parameters are enclosed between slashes and do not use quotation marks.
- The constructor function "s parameters are not enclosed between slashes, but do use quotation marks.
The following expressions create the same regular expression:
/ Ab + c / i new RegExp (/ ab + c /, "i") // literal notation new RegExp ( "ab + c", "i") // constructor
The literal notation provides a compilation of the regular expression when the expression is evaluated. Use literal notation when the regular expression will remain constant. For example, if you use literal notation to construct a regular expression used in a loop, the regular expression won "t be recompiled on each iteration.
The constructor of the regular expression object, for example, new RegExp ( "ab + c"), provides runtime compilation of the regular expression. Use the constructor function when you know the regular expression pattern will be changing, or you don "t know the pattern and are getting it from another source, such as user input.
Starting with ECMAScript 6, new RegExp (/ ab + c /, "i") no longer throws a TypeError ( "can" t supply flags when constructing one RegExp from another ") when the first argument is a RegExp and the second flags argument is present. A new RegExp from the arguments is created instead.
When using the constructor function, the normal string escape rules (preceding special characters with \ when included in a string) are necessary. For example, the following are equivalent:
Let re = / \ w + / let re = new RegExp ( "\\ w +")
Properties
RegExp.prototype Allows the addition of properties to all objects. RegExp.length The value of RegExp.length is 2. get RegExp [@@ species] The constructor function that is used to create derived objects. RegExp.lastIndex The index at which to start the next match.Methods
The global RegExp object has no methods of its own. However, it does inherit some methods through the prototype chain.
RegExp prototype objects and instances
Properties
Examples
Using a regular expression to change data format
let str = "# foo #" let regex = / foo / y regex.lastIndex = 1 regex.test (str) // true regex.lastIndex = 5 regex.test (str) // false (lastIndex is taken into account with sticky flag) regex.lastIndex // 0 (reset after match failure)Regular expression and Unicode characters
As mentioned above, \ w or \ W only matches ASCII based characters; for example, a to z, A to Z, 0 to 9, and _.
To match characters from other languages such as Cyrillic or Hebrew, use \ u hhhh, where hhhh is the character "s Unicode value in hexadecimal. This example demonstrates how one can separate out Unicode characters from a word.
Let text = "Зразок text російською мовою" let regex = / [\ u0400- \ u04FF] + / g let match = regex.exec (text) console.log (match) // logs "Зразок" console.log (regex .lastIndex) // logs "7" let match2 = regex.exec (text) console.log (match2) // logs "на" console.log (regex.lastIndex) // logs "15" // and so on
Extracting sub-domain name from URL
let url = "http://xxx.domain.com" console.log (/[^.]+/. exec (url) .substr (7)) // logs "xxx"Specifications
| Specification | Status | Comment |
|---|---|---|
| ECMAScript 3rd Edition (ECMA-262) | Standard | Initial definition. Implemented in JavaScript 1.1. |
| ECMAScript 5.1 (ECMA-262) |
Standard | |
| ECMAScript 2015 (6th Edition, ECMA-262) The definition of "RegExp" in that specification. |
Standard | The RegExp constructor no longer throws when the first argument is a RegExp and the second argument is present. Introduces Unicode and sticky flags. |
| ECMAScript Latest Draft (ECMA-262) The definition of "RegExp" in that specification. |
Draft |
Browser compatibility
The compatibility table on this page is generated from structured data. If you "d like to contribute to the data, please check out https://github.com/mdn/browser-compat-data and send us a pull request.
Регулярні виразидозволяють виробляти гнучкий пошук в рядках тексту.
створення
var expr = new RegExp (pattern [, flags]); // повна форма запису var expr = / pattern / flags; // скорочена форма запису (літеральний формат)параметри
pattern Шаблон пошуку (текст регулярного виразу). flags Способи пошуку за шаблоном:- g- глобальний пошук (обробляються всі збіги з шаблоном пошуку);
- i- Не будете звертати уваги рядкові і великі літери;
- m- багаторядковий пошук.
Коментарі
коли регулярний виразстворюється за допомогою конструктора new RegExp (...), необхідно пам'ятати, що зворотні слеші (\) повинні екрануватися, наприклад:
Var expr = new RegExp ( "\\ w", "ig");
При використанні літерального формату, цього робити не потрібно:
Var expr = / \ w / gi;
Обидві записи еквівалентні. Перший варіант може знадобиться, якщо вам доведеться генерувати регулярний вираз динамічно.
У регулярних виразах розрізняють наступні види символів:
звичайні символи
Спеціальні символи
Спецсимволи в регулярному виразі
| символ | значення |
|---|---|
| \ | Для звичайних символів - робить їх спеціальними. Наприклад, вираз / s / шукає просто символ "s". А якщо поставити \ перед s, то / \ s / вже позначає символ пробілу. І навпаки, якщо символ спеціальний, наприклад *, то \ зробить його просто звичайним символом "зірочка". Наприклад, / a * / шукає 0 або більше поспіль символів "a". Щоб знайти а із зірочкою "a *" - поставимо \ перед спец. символом: / a \ * /. |
| ^ | Позначає початок вхідних даних. Якщо встановлений прапор багаторядкового пошуку ( "m"), то також спрацює при початку нового рядка. Наприклад, / ^ A / не знайде "A" в "an A", але знайде перше "A" в "An A." |
| $ | Позначає кінець вхідних даних. Якщо встановлений прапор багаторядкового пошуку, то також спрацює в кінці рядка. Наприклад, / t $ / не знайде "t" в "eater", але знайде - в "eat". |
| * | Позначає повторення 0 або більше разів. Наприклад, / bo * / знайде "boooo" в "A ghost booooed" і "b" в "A bird warbled", але нічого не знайде в "A goat grunted". |
| + | Позначає повторення 1 або більше разів. Еквівалентно (1,). Наприклад, / a + / знайде "a" в "candy" і все "a" в "caaaaaaandy". |
| ? | Позначає, що елемент може як бути присутнім, так і бути відсутнім. Наприклад, / e? Le? / Знайде "el" в "angel" і "le" в "angle." Якщо використовується відразу після одного з квантіфікаторов *, +,? , Або (), то задає "нежадібна" пошук (повторення мінімально можлива кількість разів, до найближчого наступного елемента патерну), на противагу "жадібному" режиму за замовчуванням, при якому кількість повторень максимально, навіть якщо наступний елемент патерну теж підходить. Крім того, ? використовується в попередньому перегляді, який описаний в таблиці під (? =), (?!), і (? :). |
| . | (Десяткова точка) позначає будь-який символ, крім перекладу рядки: \ n \ r \ u2028 or \ u2029. (Можна використовувати [\ s \ S] для пошуку будь-якого символу, включаючи переклади рядків). Наприклад, /.n/ знайде "an" і "on" в "nay, an apple is on the tree", але не "nay". |
| (X) | Знаходить x і запам'ятовує. Це називається "запам'ятовуючі дужки". Наприклад, / (foo) / знайде і запам'ятає "foo" в "foo bar." Знайдена підрядок зберігається в масиві-результаті пошуку або в зумовлених властивості об'єкта RegExp: $ 1, ..., $ 9. Крім того, дужки об'єднують те, що в них знаходиться, в єдиний елемент патерну. Наприклад, (abc) * - повторення abc 0 і більше разів. |
| (?: X) | Знаходить x, але не запам'ятовує знайдене. Це називається "не запам'ятовуються дужки". Знайдена підрядок не зберігається в масиві результатів і властивості RegExp. Як і всі дужки, об'єднують що знаходиться в них в єдиний подпаттерн. |
| x (? = y) | Знаходить x, тільки якщо за x слід y. Наприклад, / Jack (? = Sprat) / знайде "Jack", тільки якщо за ним слід "Sprat". / Jack (? = Sprat | Frost) / знайде "Jack", тільки якщо за ним слід "Sprat" або "Frost". Однак, ні "Sprat" ні "Frost" не ввійдуть в результат пошуку. |
| x (?! y) | Знаходить x, тільки якщо за x не слід y. Наприклад, /\d+(?!\.)/ знайде число, тільки якщо за ним не слід десяткова крапка. /\d+(?!\.)/.exec("3.141 ") знайде 141, але не 3.141. |
| x | y | Знаходить x або y. Наприклад, / green | red / знайде "green" в "green apple" та "red" в "red apple." |
| (N) | Де n - позитивне ціле число. Знаходить рівно n повторення попереднього елемента. Наприклад, / a (2) / не знайде "a" в "candy," але знайде обидва a в "caandy," і перші два a в "caaandy." |
| (N,) | Де n - позитивне ціле число. Знаходить n і більш повторень елемента. Наприклад, / a (2,) не знайде "a" в "candy", але знайде все "a" в "caandy" і в "caaaaaaandy." |
| (N, m) | Де n і m - позитивні цілі числа. Знаходять від n до m повторень елемента. |
| Набір символів. Знаходить будь-який з перелічених символів. Ви можете вказати проміжок, використовуючи тире. Наприклад, - те ж саме, що. Чи знайде "b" в "brisket" і "c" в "ache". | |
| [^ Xyz] | Будь-який символ, крім зазначених у наборі. Ви також можете вказати проміжок. Наприклад, [^ abc] - те ж саме, що [^ a-c]. Чи знайде "r" в "brisket" і "h" в "chop." |
| [\ B] | Знаходить символ backspace. (Не плутати з \ b.) |
| \ b | Знаходить кордон слів (латинських), наприклад пробіл. (Не плутати з [\ b]). Наприклад, / \ bn \ w / знайде "no" в "noonday"; / \ Wy \ b / знайде "ly" в "possibly yesterday." |
| \ B | Позначає не кордон слів. Наприклад, / \ w \ Bn / знайде "on" в "noonday", а / y \ B \ w / знайде "ye" в "possibly yesterday." |
| \ cX | Де X - буква від A до Z. Позначає контрольний символ в рядку. Наприклад, / \ cM / позначає символ Ctrl-M. |
| \ d | знаходить цифру з будь-якого алфавіту (у нас же юнікод). Використовуйте, щоб знайти тільки звичайні цифри. Наприклад, / \ d / або // знайде "2" в "B2 is the suite number." |
| \ D | Чи знайде нецифровий символ (всі алфавіти). [^ 0-9] - еквівалент для звичайних цифр. Наприклад, / \ D / або / [^ 0-9] / знайде "B" в "B2 is the suite number." |
| \ F, \ r, \ n | Відповідні спецсимволи form-feed, line-feed, переклад рядка. |
| \ s | Знайде будь символ пробілу, включаючи пробіл, табуляцію, переклади рядки та інші Юнікодние пробільні символи. Наприклад, / \ s \ w * / знайде "bar" в "foo bar." |
| \ S | Чи знайде будь-який символ, крім пробільних. Наприклад, / \ S \ w * / знайде "foo" в "foo bar." |
| \ t | Символ табуляції. |
| \ v | Символ вертикальної табуляції. |
| \ w | Чи знайде будь-який словесний (латинський алфавіт) символ, включаючи літери, цифри і знак підкреслення. Еквівалентно. Наприклад, / \ w / знайде "a" в "apple," "5" в "$ 5.28," і "3" в "3D." |
| \ W | Знайде будь не- (лат.) Словесний символ. Еквівалентно [^ A-Za-z0-9_]. Наприклад, / \ W / і / [^ $ A-Za-z0-9 _] / однаково знайдуть "%" в "50%." |
| \ n | де n - ціле число. Зворотній посилання на n-ю запомненную дужками підрядок. Наприклад, / apple (,) \ sorange \ 1 / знайде "apple, orange," в "apple, orange, cherry, peach.". За таблицею є більш повний приклад. |
| \0 | Знайде символ NUL. Не додавайте в кінець інші цифри. |
| \ xhh | Знайде символ з кодом hh (2 шістнадцяткових цифри) |
| \ uhhhh | Знайде символ з кодом hhhh (4 шістнадцяткових цифри). |
Приклад зміни формату рядка
Var re = / (\ w +) \ s (\ w +) /; var str = "John Smith"; var newstr = str.replace (re, "$ 2, $ 1"); alert (newstr); // "Smith, John"
властивості
методи
| Виконує пошук збіги в своєму строковому параметрі. | |
| Тестує на збіг у своєму строковому параметрі. | |
А також методи об'єкта String |
|
| match | Виконує пошук збіги в рядку. Повертає масив інформації, або null при відсутності збігу. |
| search | Тестує на наявність збігів у рядку. Повертає індекс збігу або -1, якщо пошук завершився невдало. |
| replace | Виконує пошук збіги в рядку і замінює знайдені подстроки замісної підрядком. |
| split | Використовує регулярний вираз або фіксовану рядок для поділу рядка на масив підрядків. |
global
Чи використовується прапор " g"В регулярному виразі.
синтаксис
regexp.globalglobal
значення globalбуде true, якщо прапор " gg
// Визначимо довільне регулярний вираз var regexp = / Шаблон приклад / g; / * У разі якщо regexp містить модифікатор g виведемо "Модифікатор g встановлений", в іншому випадку виведемо "Модифікатор g не встановлено" * / if (regexp.global) alert ( "Модифікатор g встановлений"); else alert ( "Модифікатор g не встановлено");
ignoreCase
Чи використовується прапор " i"В регулярному виразі.
синтаксис
regexp.ignoreCaseОпис, коментарі, приклади
ignoreCaseце властивість окремого об'єкта регулярного виразу.
Ви не можете змінювати це властивість явно.
значення ignoreCaseбуде true, якщо прапор " i"Використовується; інакше - false. Прапор" i"Вказує, що регістр символів має ігноруватися при пошуку збігів в рядку.
// Визначимо довільне регулярний вираз var regexp = / Шаблон приклад / i; / * У разі якщо regexp містить модифікатор i виведемо "Модифікатор i встановлений", в іншому випадку виведемо "Модифікатор i не встановлено" * / if (regexp.ignoreCase) alert ( "Модифікатор i встановлений"); else alert ( "Модифікатор i не встановлено");
lastIndex
властивість lastIndexвказує позицію, з якої почнеться наступний пошук.
синтаксис
regexp.lastIndexКоментарі
Це властивість буде працювати тільки якщо в регулярному виразі встановлений модифікатор g.
Дана властивість повертає ціле число, яке позначає позицію останнього символу знайденого за допомогою методу або.
приклад
// Визначимо довільне регулярний вираз var str = "Я короткий рядок"; // Задамо регулярний вираз var regexp = / о / g; // Зробимо глобальний пошук "o" в рядку тексту і будемо відображати // позицію після кожного знайденого збіги while (regexp.test (str) == true) (alert (regexp.lastIndex);)multiline
Чи використовується прапор " m"В регулярному виразі.
синтаксис
regexp.globalОпис, коментарі, приклади
multilineце властивість окремого об'єкта регулярного виразу.
Ви не можете змінювати це властивість явно.
значення multilineбуде true, якщо прапор " g"Використовується; інакше - false. Прапор" g"Вказує, що регулярний вираз має перевірятися щодо всіх можливих збігів в рядку.
// Визначимо довільне регулярний вираз var regexp = / Шаблон приклад / m; / * У разі якщо regexp містить модифікатор g виведемо "Модифікатор g встановлений", в іншому випадку виведемо "Модифікатор g не встановлено" * / if (regexp.multiline) alert ( "Модифікатор m встановлений"); else alert ( "Модифікатор g не встановлено");
source
властивість sourceповертає вміст шаблону регулярного виразу